用Python从海量文本抽取主题
你在工作、学习中是否曾因信息过载叫苦不迭?有一种方法能够替你读海量文章,并将不同的主题和对应的关键词抽取出来,让你谈笑间观其大略。本文使用Python对超过1000条文本做主题抽取,一步步带你体会非监督机器学习LDA方法的魅力。想不想试试呢?

淹没¶
每个现代人,几乎都体会过信息过载的痛苦。文章读不过来,音乐听不过来,视频看不过来。可是现实的压力,使你又不能轻易放弃掉。
假如你是个研究生,教科书和论文就是你不得不读的内容。现在有了各种其他的阅读渠道,微信、微博、得到App、多看阅读、豆瓣阅读、Kindle,还有你在RSS上订阅的一大堆博客……情况就变得更严重了。
因为对数据科学很感兴趣,你订阅了大量的数据科学类微信公众号。虽然你很勤奋,但你知道自己依然遗漏了很多文章。
学习了 Python爬虫课 以后,你决定尝试一下自己的屠龙之术。依仗着爬虫的威力,你打算采集到所有数据科学公众号文章。
你仔细分析了微信公众号文章的检索方式,制定了关键词列表。巧妙利用搜狗搜索引擎的特性,你编写了自己的爬虫,并且成功地于午夜放到了云端运行。
开心啊,激动啊……
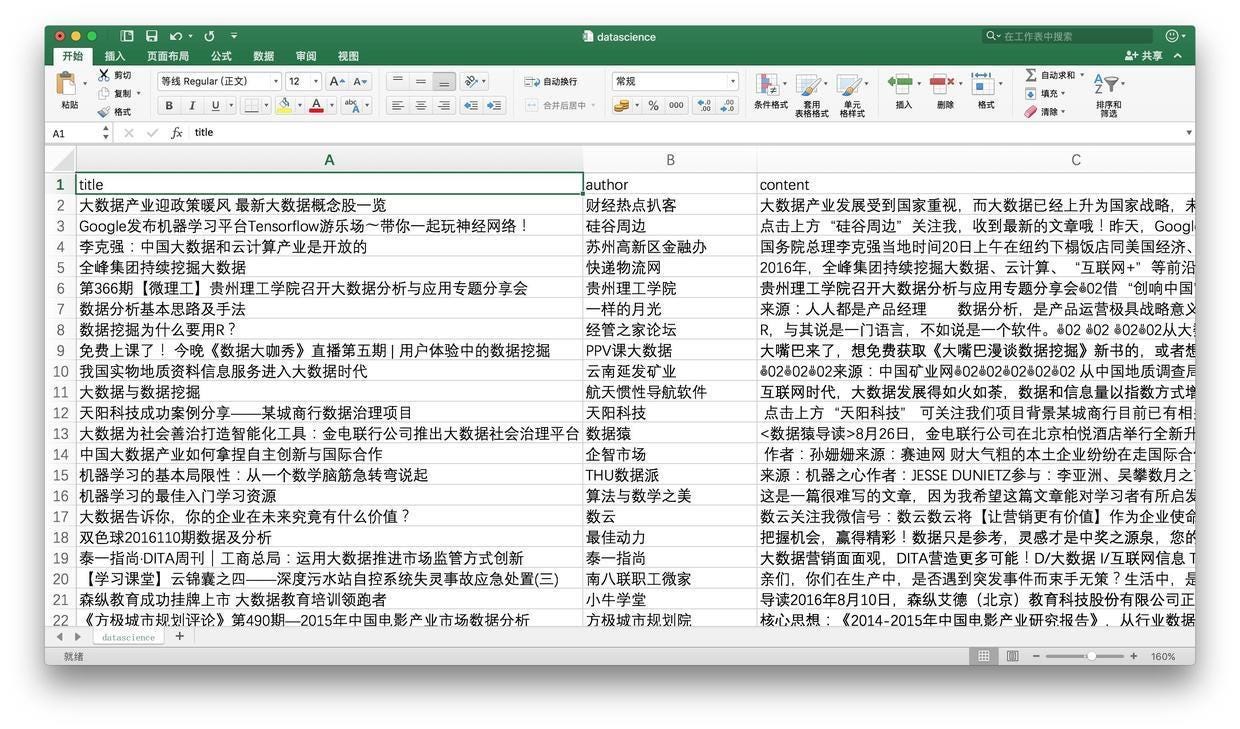
第二天一早,天光刚亮,睡眠不足的你就兴冲冲地爬起来去看爬取结果。居然已经有了1000多条!你欣喜若狂,导出成为csv格式,存储到了本地机器,并且打开浏览。
兴奋了10几分钟之后,你冷却了下来,给自己提出了2个重要的问题。
- 这些文章都值得读吗?
- 这些文章我读得过来吗?
一篇数据科学类公众号,你平均需要5分钟阅读。这1000多篇……你拿出计算器认真算了一下。
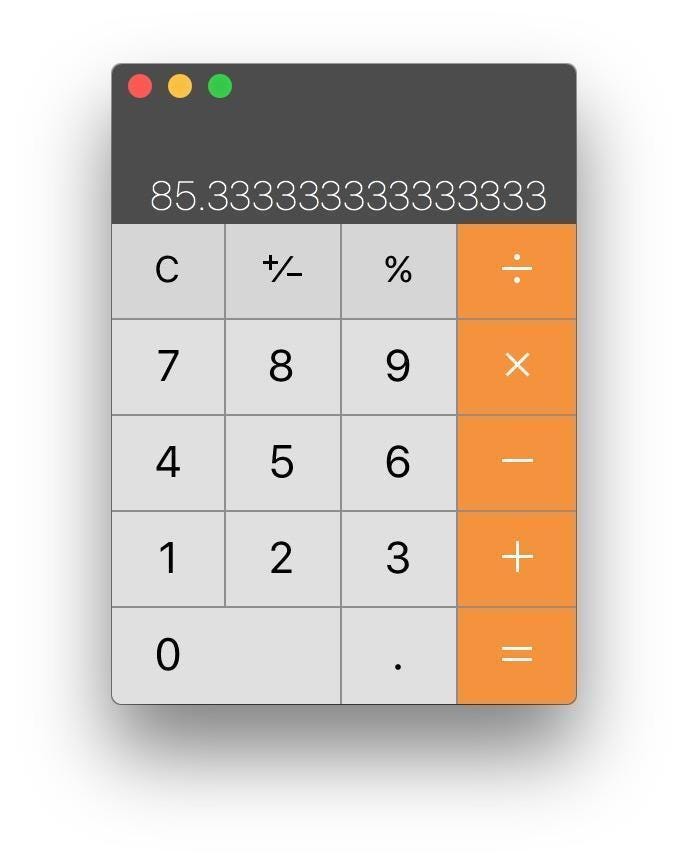
读完这一宿采集到的文章,你不眠不休的话,也需要85个小时。
在你阅读的这85个小时里面,许许多多的数据科学类公众号新文章还会源源不断涌现出来。
你感觉自己快被文本内容淹没了,根本透不过气……
学了这么长时间Python,你应该想到 — — 我能否用自动化工具来分析它?
好消息,答案是可以的。
但是用什么样的工具呢?
然而,在帮你应对信息过载这件事儿上,上述武器好像都不大合适。
词云你打算做几个?全部文章只做一个的话,就会把所有文章的内容混杂起来,没有意义 — — 因为你知道这些文章谈的就是数据科学啊!如果每一篇文章都分别做词云,1000多张图浏览起来,好像也没有什么益处。
你阅读数据科学类公众号文章是为了获得知识和技能,分析文字中蕴含的情感似乎于事无补。
决策树是可以用来做分类的,没错。可是它要求的输入信息是 结构化 的 有 标记数据,你手里握着的这一大堆文本,却刚好是 非结构化 的 无 标记数据。
全部武器都哑火了。
没关系。本文帮助你在数据科学武器库中放上一件新式兵器。它能够处理的,就是大批量的非结构无标记数据。在机器学习的分类里,它属于非监督学习(unsupervised machine learning)范畴。具体而言,我们需要用到的方法叫主题建模(topic model)或者主题抽取(topic extraction)。
主题¶
既然要建模,我们就需要弄明白建立什么样的模型。
根据维基百科的定义,主题模型是指:
在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。
这个定义本身好像就有点儿抽象,咱们举个例子吧。
还是维基百科上,对一条可爱的小狗有这样一段叙述。
阿博(Bo;2008年10月9日-) 是美国第44任总统巴拉克·奥巴马的宠物狗,也是奥巴马家族的成员之一。阿博是一只已阉割的雄性黑色长毛葡萄牙水犬。奥巴马一家本来没有养狗,因为他的大女儿玛丽亚对狗过敏。但为了延续白宫主人历年均有养狗的传统,第一家庭在入主白宫后,花了多个月去观察各种犬种,并特地选择了葡萄牙水犬这一种掉毛少的低敏狗。
我们来看看这条可爱的小狗照片:

问题来了,这篇文章的主题(topic)是什么?
你可能脱口而出,“狗啊!”
且慢,换个问法。假设一个用户读了这篇文章,很感兴趣。你想推荐更多他可能感兴趣的文章给他,以下2段文字,哪个选项更合适呢?
选项1:
阿富汗猎狗(Afghan Hound)是一种猎犬,也是最古老的狗品种。阿富汗猎狗外表厚实,细腻,柔滑,它的尾巴在最后一环卷曲。阿富汗猎狗生存于伊朗,阿富汗东部的寒冷山上,阿富汗猎狗最初是用来狩猎野兔和瞪羚。阿富汗猎狗其他名称包含巴尔赫塔子库奇猎犬,猎犬,俾路支猎犬,喀布尔猎犬,或非洲猎犬。
选项2:
1989年夏天,奥巴马在西德利·奥斯汀律师事务所担任暑期工读生期间,结识当时已是律师的米歇尔·鲁滨逊。两人于1992年结婚,现有两个女儿 — — 大女儿玛丽亚在1999年于芝加哥芝加哥大学医疗中心出生,而小女儿萨沙在2001年于芝加哥大学医疗中心出生。
给你30秒,思考一下。
你的答案是什么?
我的答案是 — — 不确定。
人类天生喜欢把复杂问题简单化。我们恨不得把所有东西划分成具体的、互不干扰的分类,就如同药铺的一个个抽屉一样。然后需要的时候,从对应的抽屉里面取东西就可以了。

这就像是职业。从前我们说“三百六十行”。随便拿出某个人来,我们就把他归入其中某一行。
现在不行了,反例就是所谓的“斜杠青年”。
主题这个事情,也同样不那么泾渭分明。介绍小狗Bo的文章虽然不长,但是任何单一主题都无法完全涵盖它。
如果用户是因为对小狗的喜爱,阅读了这篇文章,那么显然你给他推荐选项1会更理想;但是如果用户关注的是奥巴马的家庭,那么比起选项2来,选项1就显得不是那么合适了。
我们必须放弃用一个词来描述主题的尝试,转而用一系列关键词来刻画某个主题(例如“奥巴马”+“宠物“+”狗“+”第一家庭“)。
在这种模式下,以下的选项3可能会脱颖而出:
据英国《每日邮报》报道,美国一名男子近日试图绑架总统奥巴马夫妇的宠物狗博(Bo),不惜由二千多公里远的北达科他州驱车往华盛顿,但因为走漏风声,被特勤局人员逮捕。奥巴马夫妇目前养有博和阳光(Sunny)两只葡萄牙水犬。
讲到这里,你大概弄明白了主题抽取的目标了。可是面对浩如烟海的文章,我们怎么能够把相似的文章聚合起来,并且提取描述聚合后主题的重要关键词呢?
主题抽取有若干方法。目前最为流行的叫做隐含狄利克雷分布(Latent Dirichlet allocation),简称LDA。
LDA相关原理部分,置于本文最后。下面我们先用Python来尝试实践一次主题抽取。如果你对原理感兴趣,不妨再做延伸阅读。
准备¶
准备工作的第一步,还是先安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云 》一文。
从微信公众平台爬来的datascience.csv文件,请从 这里 下载。你可以用Excel打开,看看下载是否完整和正确。
如果一切正常,请将该csv文件移动到咱们的工作目录demo下。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
运行环境配置完毕。
在终端或者命令提示符下键入:
Jupyter Notebook已经正确运行。下面我们就可以正式编写代码了。
代码¶
我们在Jupyter Notebook中新建一个Python 2笔记本,起名为topic-model。
为了处理表格数据,我们依然使用数据框工具Pandas。先调用它。
然后读入我们的数据文件datascience.csv,注意它的编码是中文GB18030,不是Pandas默认设置的编码,所以此处需要显式指定编码类型,以免出现乱码错误。
我们来看看数据框的头几行,以确认读取是否正确。
显示结果如下:

没问题,头几行内容所有列都正确读入,文字显式正常。我们看看数据框的长度,以确认数据是否读取完整。
执行的结果为:
行列数都与我们爬取到的数量一致,通过。
下面我们需要做一件重要工作 — — 分词。这是因为我们需要提取每篇文章的关键词。而中文本身并不使用空格在单词间划分。此处我们采用“结巴分词”工具。这一工具的具体介绍和其他用途请参见《如何用Python做中文分词?》一文。
我们首先调用jieba分词包。
我们此次需要处理的,不是单一文本数据,而是1000多条文本数据,因此我们需要把这项工作并行化。这就需要首先编写一个函数,处理单一文本的分词。
有了这个函数之后,我们就可以不断调用它来批量处理数据框里面的全部文本(正文)信息了。你当然可以自己写个循环来做这项工作。但这里我们使用更为高效的apply函数。如果你对这个函数有兴趣,可以点击这段教学视频查看具体的介绍。
下面这一段代码执行起来,可能需要一小段时间。请耐心等候。
执行过程中可能会出现如下提示。没关系,忽略就好。
执行完毕之后,我们需要查看一下,文本是否已经被正确分词。
结果如下:
单词之间都已经被空格区分开了。下面我们需要做一项重要工作,叫做文本的向量化。
不要被这个名称吓跑。它的意思其实很简单。因为计算机不但不认识中文,甚至连英文也不认识,它只认得数字。我们需要做的,是把文章中的关键词转换为一个个特征(列),然后对每一篇文章数关键词出现个数。
假如这里有两句话:
I love the game.
I hate the game.
那么我们就可以抽取出以下特征:
- I
- love
- hate
- the
- game
然后上面两句话就转换为以下表格:

第一句表示为[1, 1, 0, 1, 1],第二句是[1, 0, 1, 1, 1]。这就叫向量化了。机器就能看懂它们了。
原理弄清楚了,让我们引入相关软件包吧。
处理的文本都是微信公众号文章,里面可能会有大量的词汇。我们不希望处理所有词汇。因为一来处理时间太长,二来那些很不常用的词汇对我们的主题抽取意义不大。所以这里做了个限定,只从文本中提取1000个最重要的特征关键词,然后停止。
下面我们开始关键词提取和向量转换过程:
到这里,似乎什么都没有发生。因为我们没有要求程序做任何输出。下面我们就要放出LDA这个大招了。
先引入软件包:
然后我们需要人为设定主题的数量。这个要求让很多人大跌眼镜 — — 我怎么知道这一堆文章里面多少主题?!
别着急。应用LDA方法,指定(或者叫瞎猜)主题个数是必须的。如果你只需要把文章粗略划分成几个大类,就可以把数字设定小一些;相反,如果你希望能够识别出非常细分的主题,就增大主题个数。
对划分的结果,如果你觉得不够满意,可以通过继续迭代,调整主题数量来优化。
这里我们先设定为5个分类试试。
把我们的1000多篇向量化后的文章扔给LDA,让它欢快地找主题吧。
这一部分工作量较大,程序会执行一段时间,Jupyter Notebook在执行中可能暂时没有响应。等待一会儿就好,不要着急。
程序终于跑完了的时候,你会看到如下的提示信息:
可是,这还是什么输出都没有啊。它究竟找了什么样的主题?
主题没有一个确定的名称,而是用一系列关键词刻画的。我们定义以下的函数,把每个主题里面的前若干个关键词显示出来:
定义好函数之后,我们暂定每个主题输出前20个关键词。
以下命令会帮助我们依次输出每个主题的关键词表:
执行效果如下:
在这5个主题里,可以看出主题0主要关注的是数据科学中的算法和技术,而主题4显然更注重数据科学的应用场景。
剩下的几个主题可以如何归纳?作为思考题,留给你花时间想一想吧。
到这里,LDA已经成功帮我们完成了主题抽取。但是我知道你不是很满意,因为结果不够直观。
那咱们就让它直观一些好了。
执行以下命令,会有有趣的事情发生。
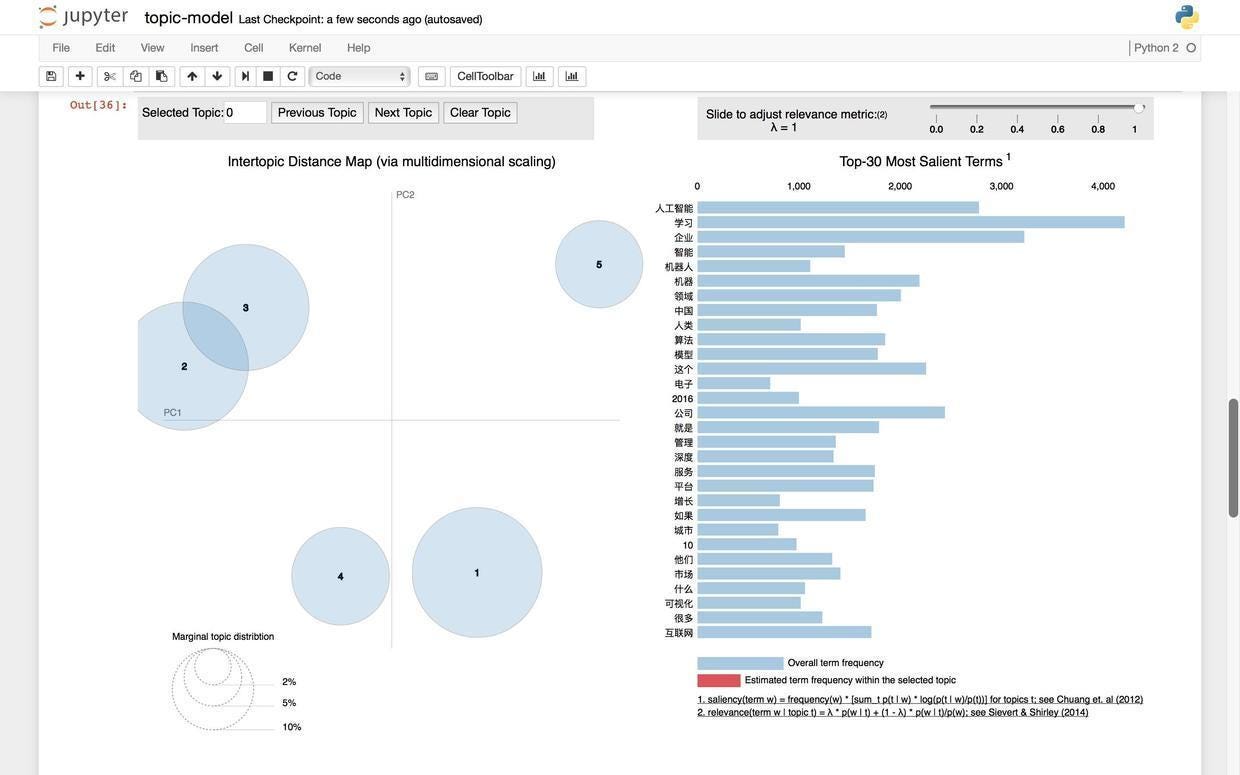
对,你会看到如下的一张图,而且还是可交互的动态图哦。
需要说明的是,由于pyLDAvis这个包兼容性有些问题。因此在某些操作系统和软件环境下,你执行了刚刚的语句后,没有报错,却也没有图形显示出来。
没关系。这时候请你写下以下语句并执行:
Jupyter会给你提示一些警告。不用管它。因为此时你的浏览器会弹出一个新的标签页,结果图形会在这个标签页里正确显示出来。
如果你看完了图后,需要继续程序,就回到原先的标签页,点击Kernel菜单下的第一项Interrupt停止绘图,然后往下运行新的语句。
图的左侧,用圆圈代表不同的主题,圆圈的大小代表了每个主题分别包含文章的数量。
图的右侧,列出了最重要(频率最高)的30个关键词列表。注意当你没有把鼠标悬停在任何主题之上的时候,这30个关键词代表全部文本中提取到的30个最重要关键词。
如果你把鼠标悬停在1号上面:
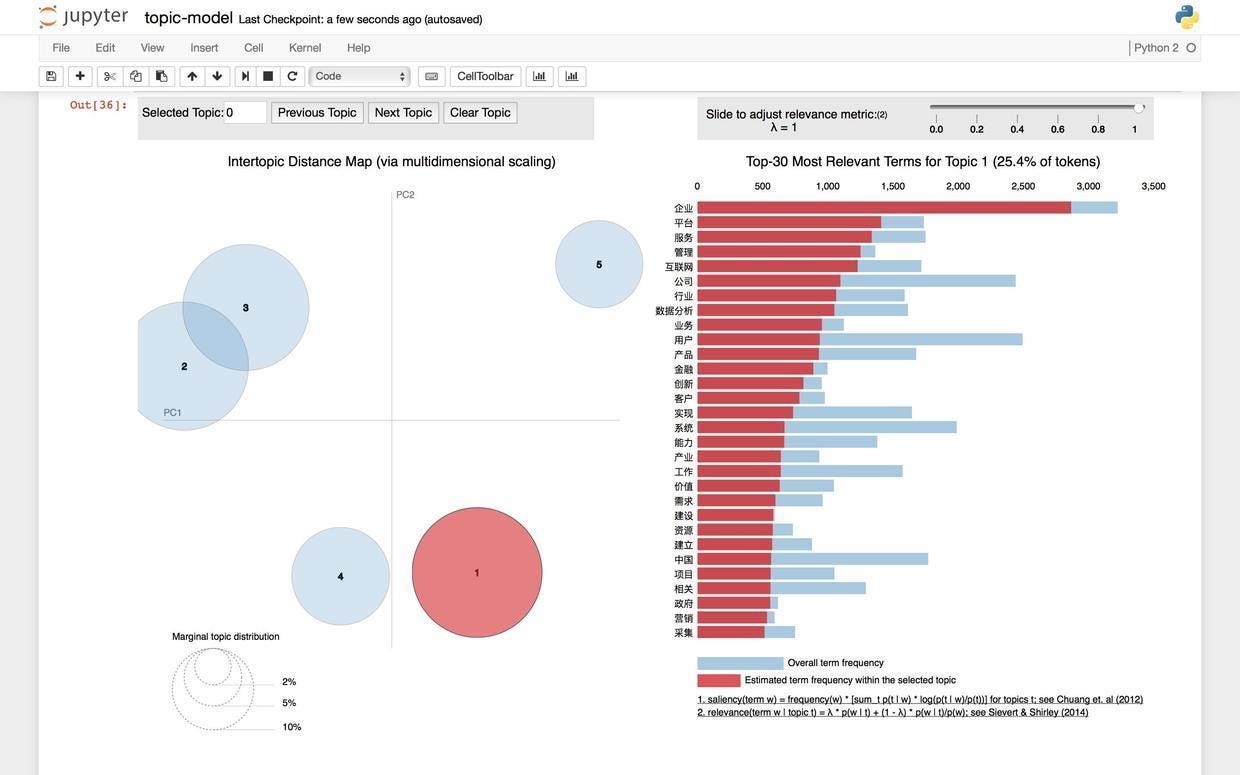
右侧的关键词列表会立即发生变化,红色展示了每个关键词在当前主题下的频率。
以上是认为设定主题数为5的情况。可如果我们把主题数量设定为10呢?
你不需要重新运行所有代码,只需要执行下面这几行就可以了。
这段程序还是需要运行一段时间,请耐心等待。
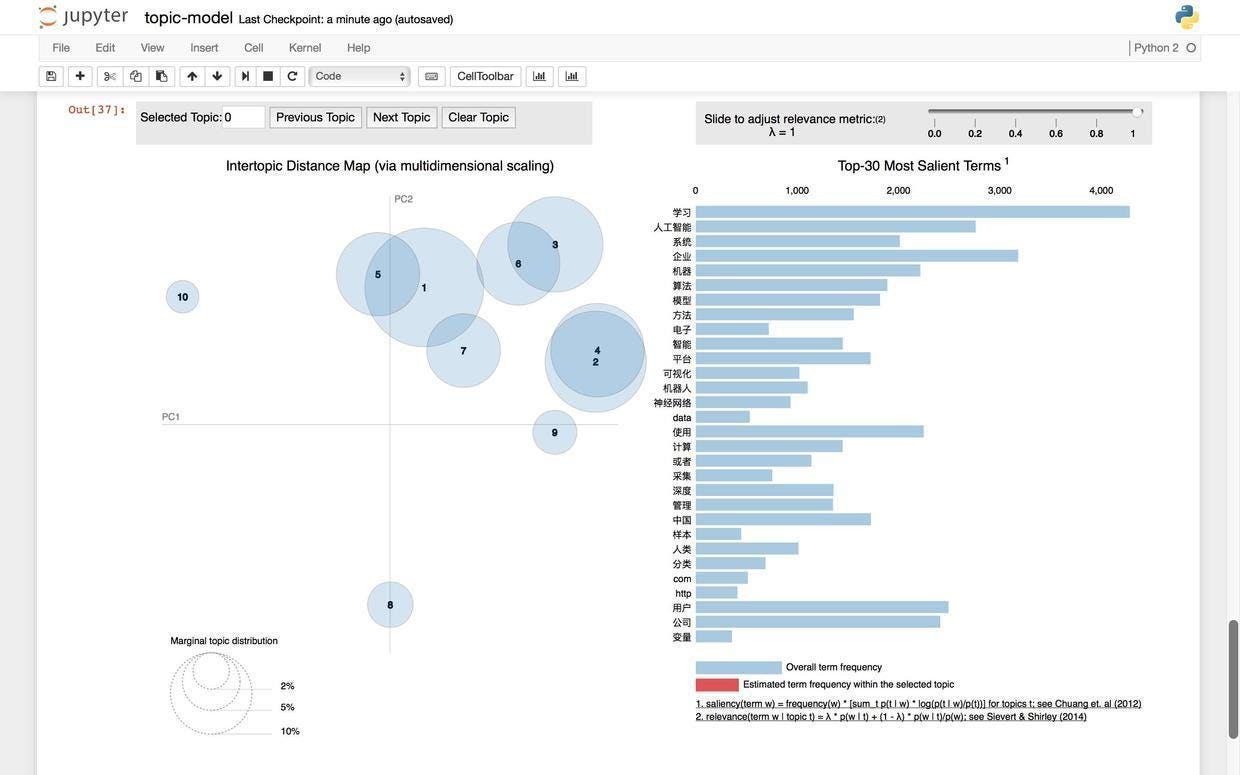
程序输出给我们10个主题下最重要的20个关键词。
附带的是可视化的输出结果:
如果不能直接输出图形,还是按照前面的做法,执行:
你马上会发现当主题设定为10的时候,一些有趣的现象发生了 — — 大部分的文章抱团出现在右上方,而2个小部落(8和10)似乎离群索居。我们查看一下这里的8号主题,看看它的关键词构成。
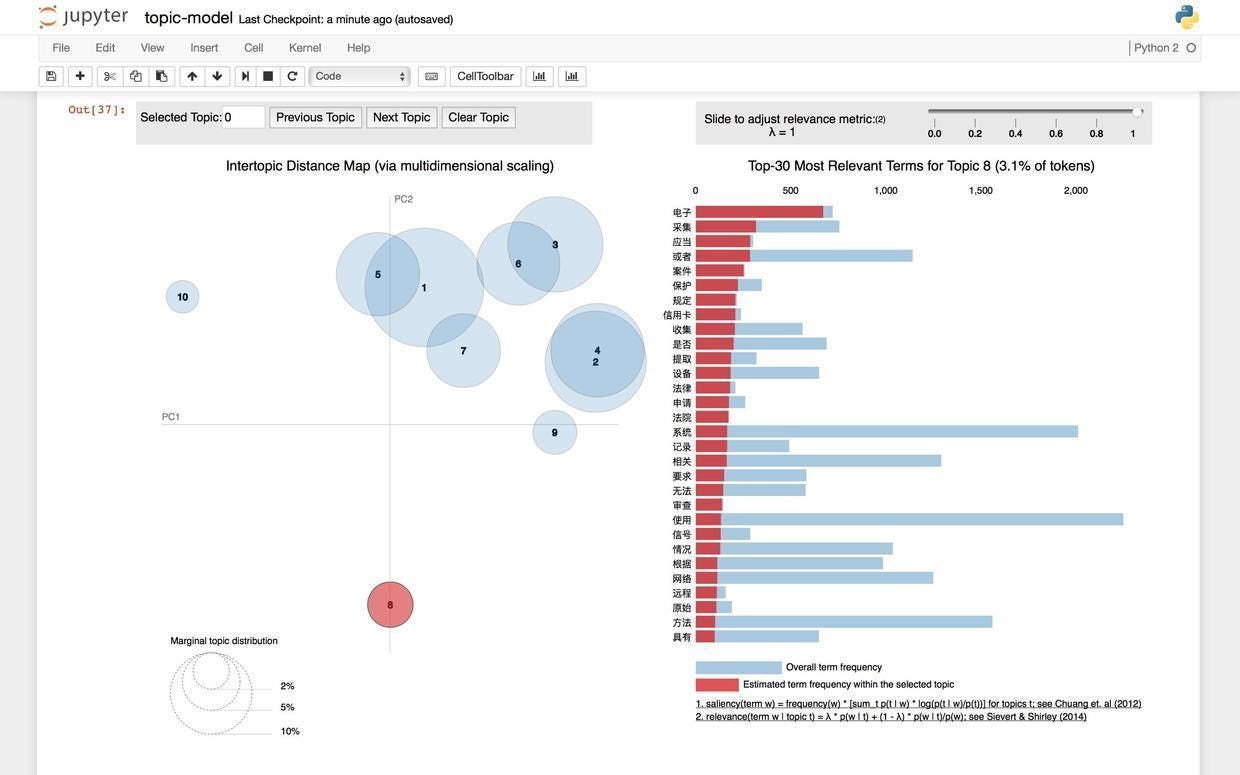
通过高频关键词的描述,我们可以猜测到这一主题主要探讨的是政策和法律法规问题,难怪它和那些技术、算法与应用的主题显得如此格格不入。
说明¶
前文帮助你一步步利用LDA做了主题抽取。成就感爆棚吧?然而这里有两点小问题值得说明。
首先,信息检索的业内专家一看到刚才的关键词列表,就会哈哈大笑 — — 太粗糙了吧!居然没有做中文停用词(stop words)去除!没错,为了演示的流畅,我们这里忽略了许多细节。很多内容使用的是预置默认参数,而且完全忽略了中文停用词设置环节,因此“这个”、“如果”、“可能”、“就是”这样的停用词才会大摇大摆地出现在结果中。不过没有关系,完成比完美重要得多。知道了问题所在,后面改进起来很容易。有机会我会写文章介绍如何加入中文停用词的去除环节。
另外,不论是5个还是10个主题,可能都不是最优的数量选择。你可以根据程序反馈的结果不断尝试。实际上,可以调节的参数远不止这一个。如果你想把全部参数都搞懂,可以继续阅读下面的“原理”部分,按图索骥寻找相关的说明和指引。
原理¶
前文我们没有介绍原理,而是把LDA当成了一个黑箱。不是我不想介绍原理,而是过于复杂。
只给你展示其中的一个公式,你就能管窥其复杂程度了。
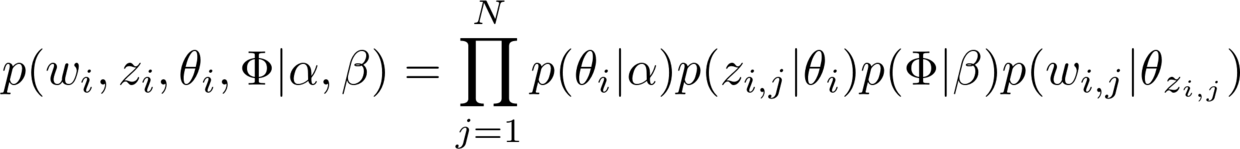
透露给你一个秘密:在计算机科学和数据科学的学术讲座中,讲者在介绍到LDA时,都往往会把原理这部分直接跳过去。
好在你不需要把原理完全搞清楚,再去用LDA抽取主题。
这就像是学开车,你只要懂得如何加速、刹车、换挡、打方向,就能让车在路上行驶了。即便你通过所有考试并取得了驾驶证,你真的了解发动机或电机(如果你开的是纯电车)的构造和工作原理吗?
但是如果你就是希望了解LDA的原理,那么我给你推荐2个学起来不那么痛苦的资源吧。
首先是教程幻灯。slideshare是个寻找教程的好去处。 这份教程 浏览量超过20000,内容深入浅出,讲得非常清晰。
但如果你跟我一样,是个视觉学习者的话,我更推荐你看 这段 Youtube视频。
讲者是Christine Doig,来自Continuum Analytics。咱们一直用的Python套装Anaconda就是该公司的产品。
Christine使用的LDA原理解释模型,不是这个LDA经典论文中的模型图(大部分人觉得这张图不易懂):
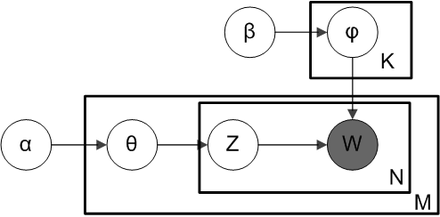
她深入阅读了各种文献后,总结了自己的模型图出来:
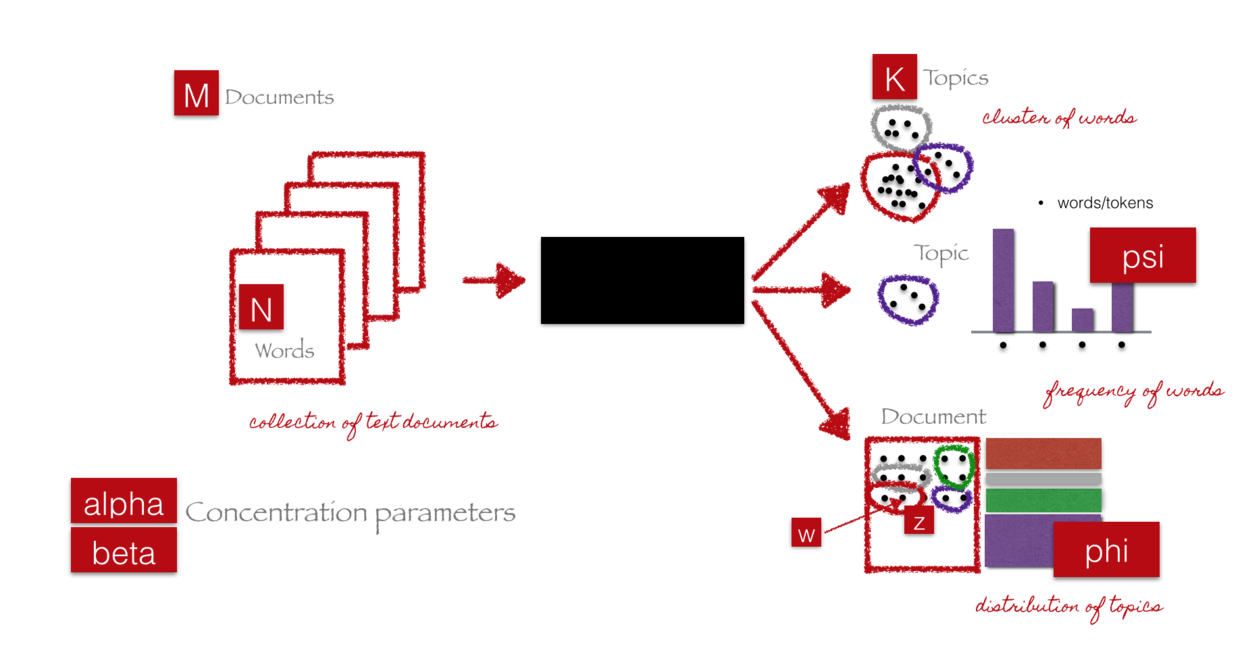
用这个模型来解释LDA,你会立即有豁然开朗的感觉。
祝探索旅程愉快!