AI绘图新秀Leonardo.ai¶
现在的AI绘图主流基本被两个产品牢牢把控了。
Midjouney 和 Stable Diffusion WebUI。

但是,这两个产品对于大家来说,门槛都还是非常高。
Midjouney虽然用起来傻瓜,封神的V5模型也能应对绝大数需求, 但是使用需要魔法,同时每个月高昂的30美刀的价格也让很多人望而却步 。
而SD更别提了, 2060 6G显卡以上的Windows电脑,就这一条,卡死了无数的人。 而随后的上手难度,更是卡死了另一拨人,即使傻瓜式教程已经铺天盖地,但是还是难。
基于这些痛点,3月初机缘巧合的从朋友那听说了Leonardo.ai,在使用了近1个月左右,在此也想推荐给大家,因为他完美的解决了以上痛点。

网址在此:https://leonardo.ai/,目前内测中。
Leonardo是一个AI绘图社区,同时也是一个绘图工具。对Stable Diffusion了解的比较多的人可能会知道一个Stable Diffusion的社区网站 - Civita。 而Leonardo更像是Civta和Stable Diffusion的集合体。

Leonardo是基于Stable Diffusion的网站,同时深度集成了Stable Diffusion的各种插件,比如ControlNET的openpose姿势参考、局部重绘、prompt提示等等,甚至还提供了傻瓜式在线训练自己模型的功能。
最关键的是,Leonardo这玩意,他不需要魔法,而且还免费。
平台采用代币制,每人每天150个token,渲染一张图大概3~8token不等,基本上如果不是高频式的疯狂用,一天绝对够了。我总结了关于Leonardo的几个特色和有趣的地方,大家也可以上去自己深度体验一下。
一. Leonardo的特色模型

Leonardo最有趣的一点就在于,他们有很多非常精良的微调模型,都是基于v1.5和v2.1微调而来,在某一个领域极其专精,比如为对像素风专精的Pixel Art、对角色专精的RPG 4.0,甚至还有对专门做斧子的Battle Axes。这跟Midjouney的超大型V5走了两种完全不同的路。

你可以直接点击button就可以调用此模型去生成自己的图片。每个模型下也都有用户创建的例子给予你做参考。
二. 快速抄作业
Leonardo借鉴(抄袭)了Civta的核心功能,当用户看到一张自己很喜欢的图时,点开,就可以直接看到这个图用了什么模型,使用了了什么prompt,你可以直接点击remix照抄再复刻一张,也可以把prompt给copy下来。这里看到一个非常可爱的小脑斧,我们试一下。
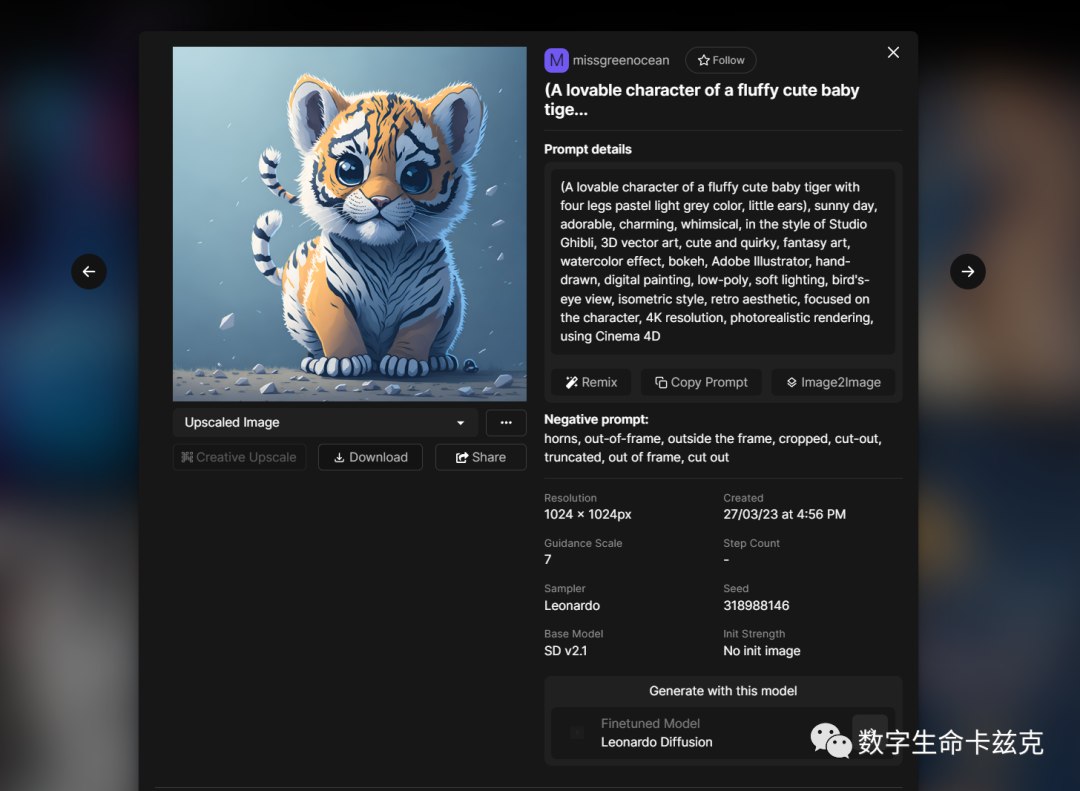
点击Remix。直接进到了生成页,把prompt和所用模型、使用参数给带了过去。
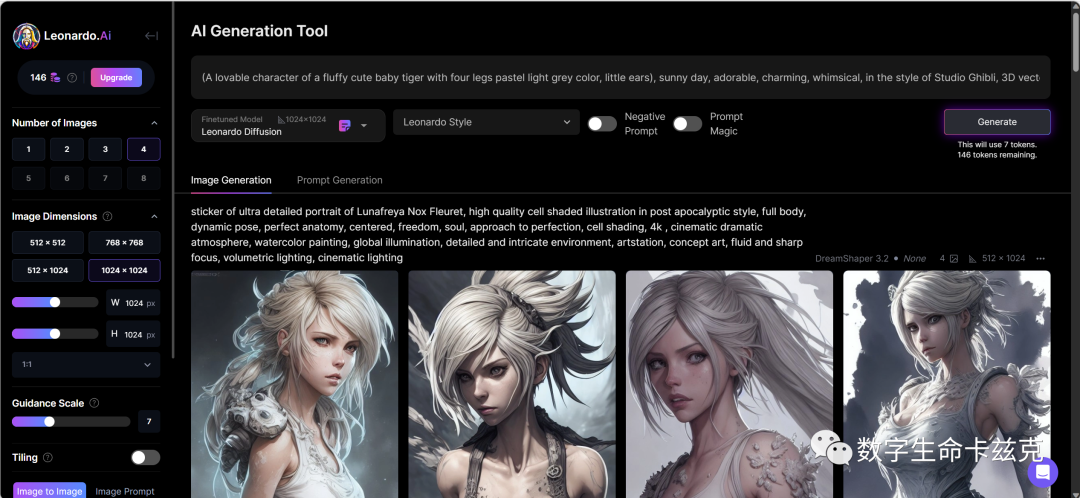
我们只要无脑点击一下Generate,这个小脑斧还挺贵,生成居然会花费7个token。等待十几秒后,你专属的可爱的小脑斧就出现啦!

三. 提示词扩展
相信大家都有写不出提示词的时候,或者只有一个想法,比如“科幻世界的女武神”这种笼统的词语。在Midjouney的环境下,可能就需要接触ChatGPT的prompt了,比如我写的这篇里的例子:我花了100个小时,整理并撰写了一份ChatGPT的超实用prompt大全...
但是Leonardo借鉴(抄袭)了Stable Diffusion WebUI的提示词插件,可以直接将想法进行拓展。
比如我们想画一个“赛博朋克钢铁侠”,直接扔给Leonardo,他就可以帮我们生成至多25个prompt。

我们选第二个去跑一下试试效果。

效果还不错~
四. 一键去背景
用我们刚才生成的小脑斧举个例子,在某些场景下,我们需要把主人物给抠出来,合成到别的背景上。扔到PS里去扣或者用别的工具,总归是很麻烦。
Leonardo提供了快捷的方式,点一下,花费2token,直接一键抠图。
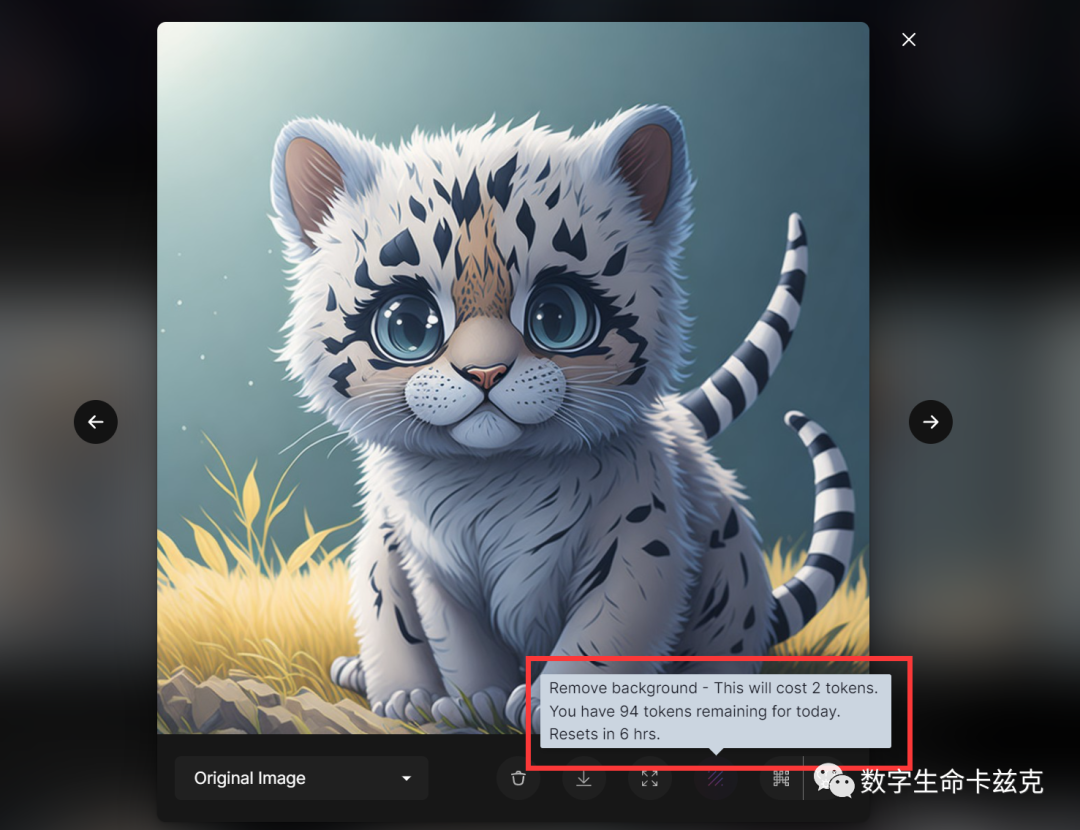
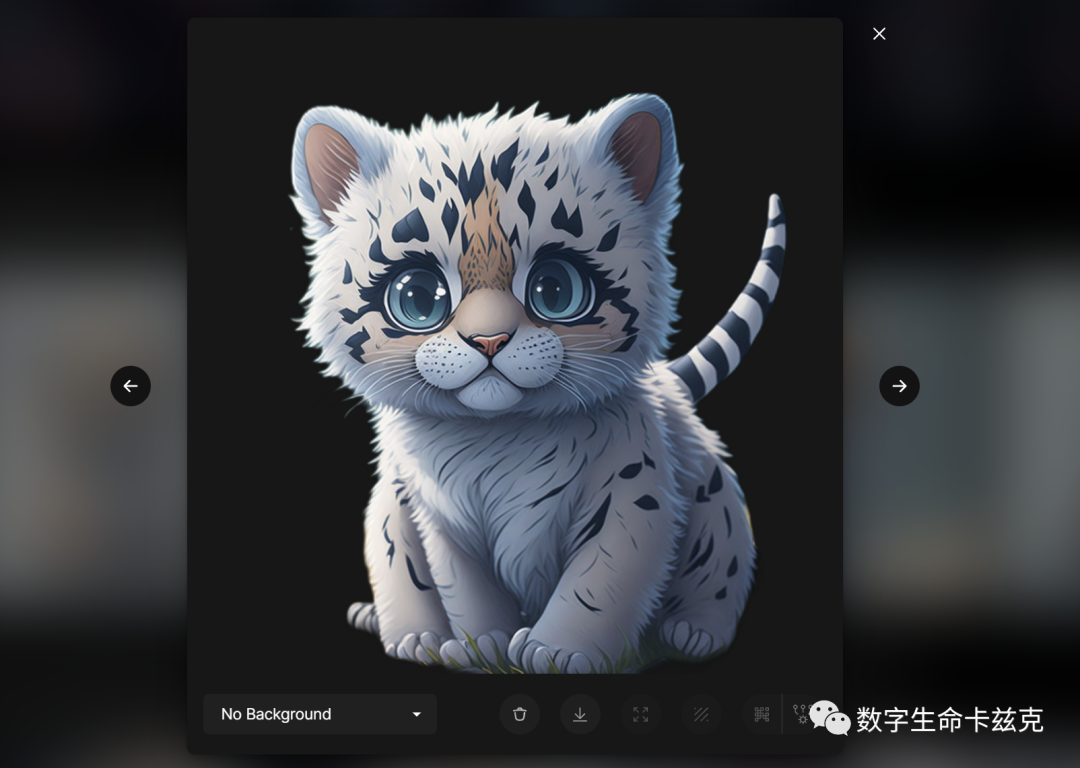
只需要点一下,我们就获得了超级干净的小脑斧PNG图,就是这么方便!
五.画板编辑
我们生成了自己想要的图片,但是很有可能,这些图的细节距离我们想要的,还是有一些距离,Leonardo也提供了一个有趣的能力,去画板中编辑。
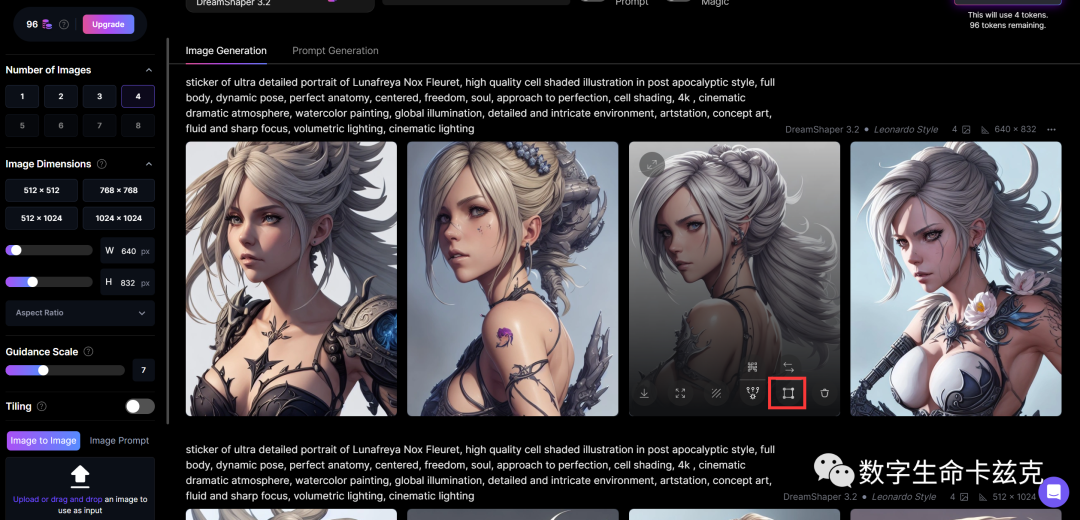
在画板中,比如我们现在觉得这张生成图的构图不太好,人物太贴边了,我们想在左边再额外渲染一些背景把构图补全,我们只要把图片拖到渲染框中,把需要格外渲染额地方给空出来,Leonardo就可以自动补齐。
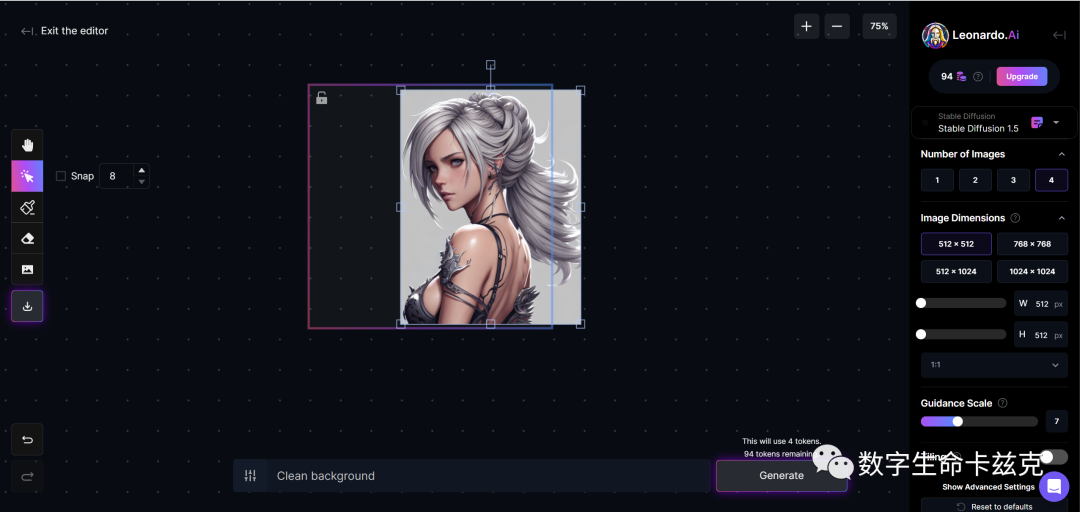
当然,画板中还有其他很多有趣的小工具,比如局部重绘、消除等等,就留给大家自己去探索啦。
六.姿势复刻
在我的这篇文章中:AI绘图傻瓜指南 - 5分钟教你用ControlNET让妹子摆出你想要的pose,详细的介绍了Stable Diffusion的神级插件ControNET,他有个最强的模型叫Openpose,可以抽取参考图的骨骼,让新生成的图片按照骨骼去去复刻人物姿势。
而Leonardo借鉴(抄袭)了这一点,集成到了自己的产品中,在我们将图片上传到Image to Image后,就能看到Pose to Image,开启他,就能完美复刻人物的动作啦。

七.训练自己的模型
这个应该是Leonardo的王炸了,在其他的任何产品上,训练自己的模型都不是一件容易的事。
Midjouney直接不支持,而Stable Diffusion则需要非常专业的知识,麻烦的要死。
现在,Leonardo提供了极其快捷的方式,去训练我们自己的模型。
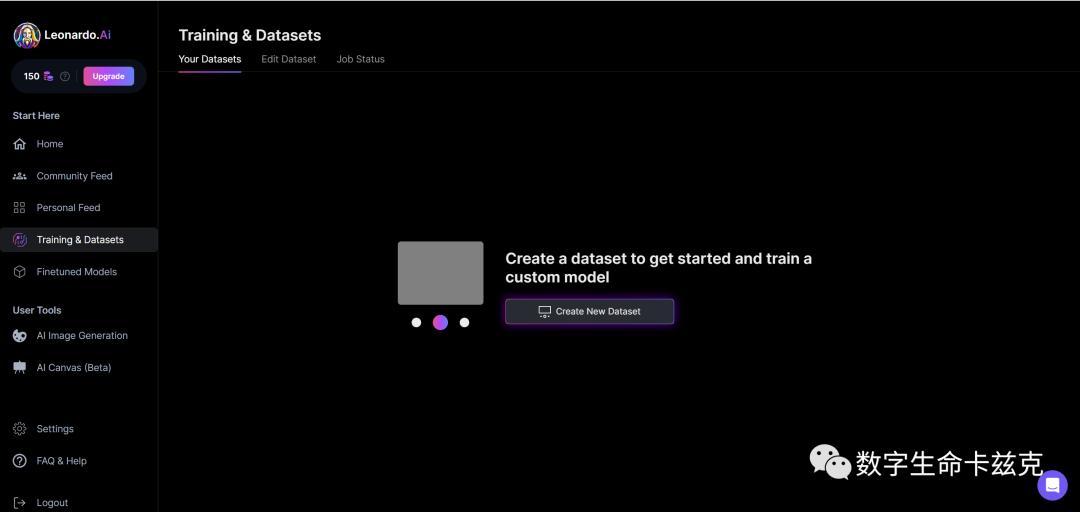

我们创建一个新的模型,取名就叫我最喜欢的最终幻想吧。
我们准备好训练集,20~40张背景干净的图片就可以。这里我选用的最终幻想画师大佬的立绘。

我们把这些训练集给传上去,直接右下角训练模型就好。最后补完一些信息,直接start,大概等30分钟左右就OK,训练完成了,会直接给邮箱发通知。
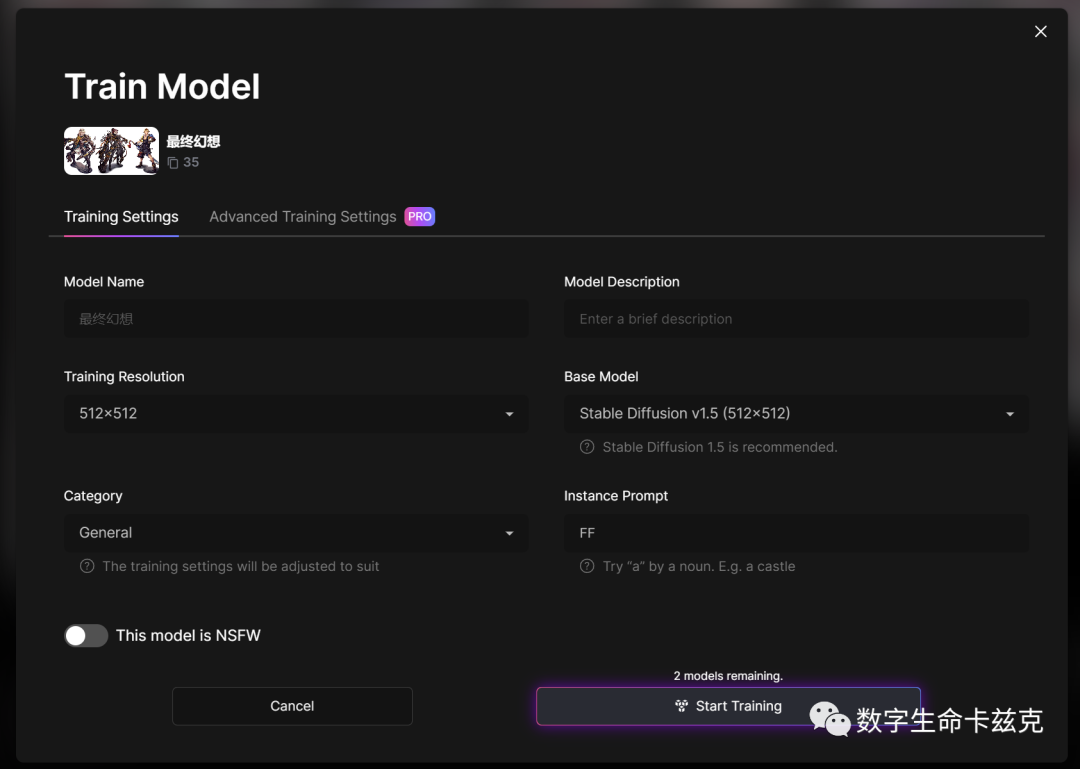
训练完成以后,我们可以在“你的模型”中找到你训练好的模型。最后跑一下
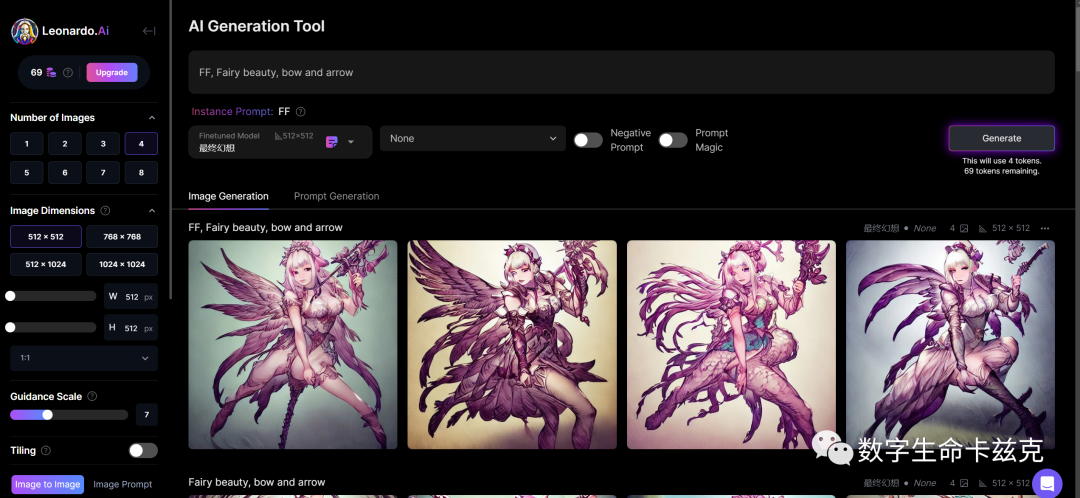
跟训练集的画风完全一样(细节还是需要调整)~
最后。
大家想用的话,直接在官网https://leonardo.ai/,点击右上角启动app,然后点击我已在白名单中,直接注册账号,就可以进了。

希望大家都能加入AI绘图的阵营。
诚然,Leonardo目前还远没有能到达跟Midjouney掰掰手腕的地步,但是,别忘了, Leonardo的背后可是Stable Diffusion,这是一个开源的算法,全球百万人共建的算法和产品,全世界进化速度最快的AI绘图,没有之一。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: 数字生命卡兹克
来源: https://zhuanlan.zhihu.com/p/618911569