量化投资入门系列(七)——基于机器学习的股票走势预测¶
引言¶
基于因子的IC值等信息,可以筛选出一系列有效的因子,而在实际使用中,将这些因子整合在一起,显然比只使用某个因子更加具有效果。而将因子整合起来,形成更为直接的买卖信号,就需要依托于机器学习模型来进行。
在机器学习引入量化领域的早期,受制于计算能力,通常使用的是较为简单的模型,例如logistic回归,SVM以及决策树等,然而一个显而易见的事实是股票市场的机制过于负责,依托于简单的模型想要取得战胜市场的效果是基本不可能的,因此更为复杂的模型开始被引入量化领域,这其中,最具代表性的就是梯度提升树和神经网络,本文将对机器学习模型在股票走势的预测做相应的阐述。
如何进行打标?¶
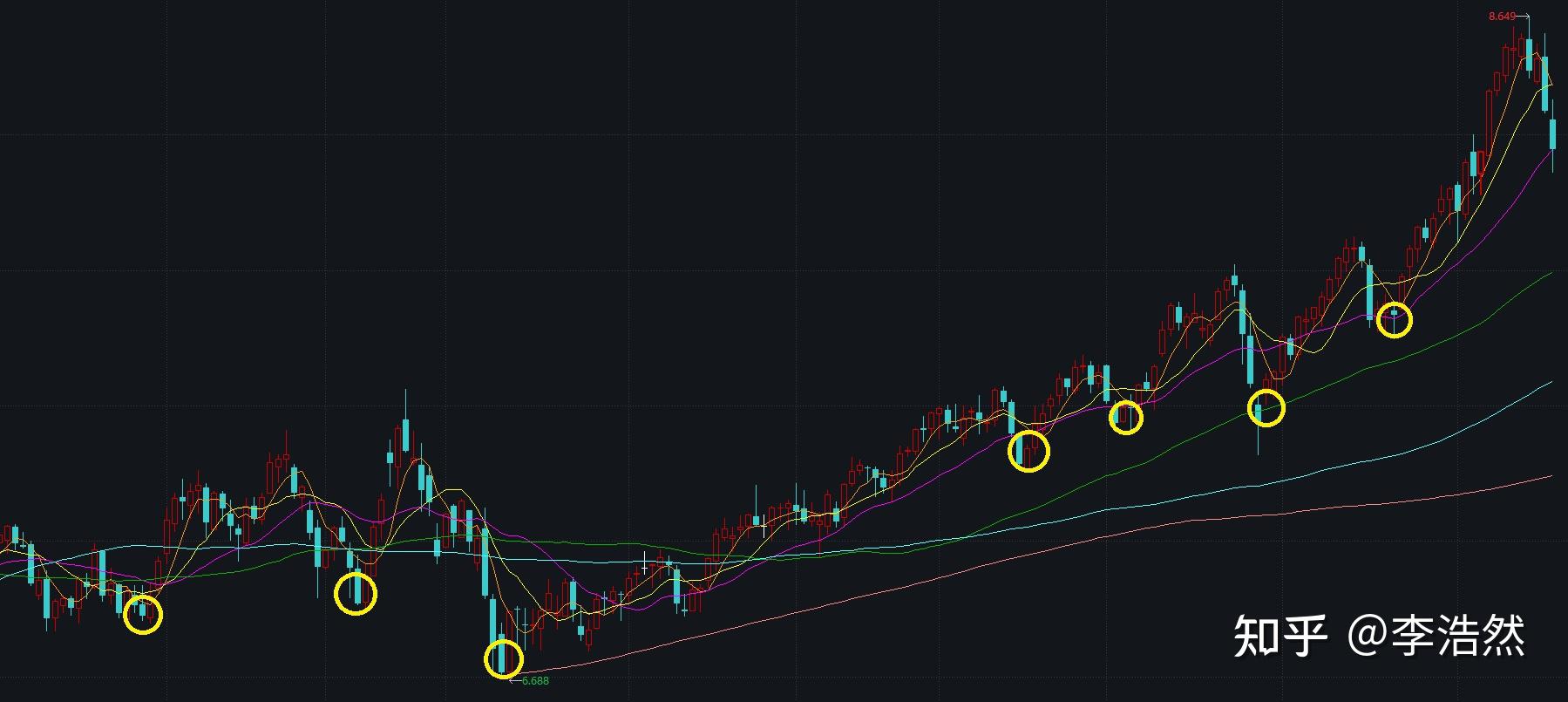
利用机器学习进行股票走势上的预测,本质上属于监督学习,所谓监督学习,指的就是在历史的数据中,给定了特征以及对应的标签,然后由机器学习模型来建立起特征与标签之间的映射。例如,给定一张动物照片,那么照片中每个像素的数据就是特征,而这张照片中的动物是猫还是狗是就是对应的标签。在机器学习所应用的其他领域,特征所对应的标签是十分明确的,借用上面的例子,这张照片中的动物究竟是猫还是狗,我们通过人眼是可以确定下来的,基本不存在什么争议。但是在量化领域,事情却变得复杂了起来,以中证500ETF为例,下图所示的是该标的在2020年12月以来的走势,在我们直接的观察中,很显然以黄色圆圈所圈出的点为合适的买入点,我们的标签似乎是明确的,但是股票数据的数据量是极为庞大的,通过人眼一只票一只票地从大量的找出类似于黄圈的点,然后制作数据集是完全不现实的,因此常用的方法是确定一套规则,然后编写程序依据规则来给定标签,则我们的问题最终落脚到了确定一套怎样的规则。
一个想当然的做法是设定一个阈值 \( threshold \) ,在任意一天(T日),获取前一日的收盘价 \( close_{T-1} \) 和n日后的收盘价 \( close_{T+n} \) ,计算期间的涨跌幅 \( \frac{close_{T+n}-close_{T-1}}{close_{T-1}} \) 或 \( log(\frac{close_{T+n}}{close_{T-1}}) \),然后与阈值作比较,大于阈值的,给定标签1,小于阈值的给定标签0,这种做法是最直观也最简单的方法,但是简单的背后,必然隐藏了诸多的问题,以下图为例,当我们在黄色框的位置看未来,依据规则,很容易得出要买入的标签,但是实际上,该点买入会首先经历一段明显的下跌过程,很容易就触发了策略的止损机制。针对这一问题,解决的方法有两个,第一个方法的思路是“先到先得”,也就是我们在计算涨幅的过程中,并不是固定地看第n日的情况,而是看在区间内,先向上突破了阈值,还是先向下突破了阈值,这种处理方式基本适用于三分类。第二个方法是看面积,将T-1日的价格划横线,然后比较曲线下的面积和曲线上的面积。

而上述打标方式的另一个问题就是,标签对于阈值过于敏感,导致模型在建立映射个过程中出现干扰,例如,将阈值设定为3%,那么对于后续涨幅为2.9%的样本,和涨幅为3.1%的样本,其很可能具有极为相似的特征,两者的差异仅仅来自于噪声,将他们划分到两个类别里,引发的问题就是模型即使在训练中都无法有效地区分两者特征的差异,从而影响模型的性能,对于这一问题,一个有效的处理方法就是设定一定的gap,并舍弃一定的数据,例如,我们可以将阈值设定为3%,然后将涨幅大于3%的归为一类,然后设定另一个阈值2%,并将涨幅小于2%的样本归为一类,然后将2%与3%之间的样本进行舍弃,从而在一定程度上降低了两类样本之间的特征相似程度。
以上列举出了简单的打标方式所引发的问题和调整的方法,但是在打标过程中所面临的问题远不止此,比如阈值、期限以及gap等各个参数设定为多少,分类选择二分类还是三分类甚至更多分类,如何尽可能地规避噪声的影响,更多地问题,还需要在实践中不断摸索和解决。总而言之,如何打标,是量化研究过程中一个至关重要而又经常被忽略的问题,当我们可以确定一个有效地打标方式,差不多就完成了80%的工作。
为什么不选择回归?
前面讨论了很多在分类模型的使用中所面临的问题,那么自然会有一个其他的疑问,为什么不选择回归。关于这个问题,一个比较通俗易懂的解释是,基于模型进行回归的结果,我们很难去衡量回归的效果,一方面,受制于涨跌幅的限制,我们的回归误差本身就已经被限制在了10%以内,而大多数的标的当日的涨跌幅平均不会超过2%,所以即使模型无脑地去预测次日股价不发生变化,那么他的误差也基本不会超过2%,网络上有大量的用回归去进行预测的,然后也会摆出一张预测结果与股价实际走势的比较图,看上去两者贴的十分紧密,给了我们模型预测的很准确的错觉,实际上只是因为这个误差就不可能很大,模型可能压根没学到太多有价值的东西,预测结果也完全没有参考价值;另一方面,在回归的过程中,一般使用的都是mae或者mse这两个损失函数,这就意味着,我们预测的结果,出现在实际涨跌幅的上方,或者下方,在计算损失的时候是完全等价的,但是在实际操作的过程中,上下的区别,可能引起了我们对涨跌的大方向的判断失误。除此之外,一个标的,如果通过分类预测涨跌方向都预测不对,那么预测到底涨跌了多少很显然是更加困难的。
使用GAN会有效吗?
既然在进行分类或回归的过程中,打标有着很大的问题,那么是否可以通过GAN生成序列来将上述问题规避掉呢?笔者的意见是,生成序列本身可能是一个可以去尝试的方向,但不能通过GAN来生成,GAN本身会包括两个网络,一个是生成网络,一个是鉴别网络,生成网络的目的是使生成的序列和原始序列尽可能接近,而鉴别网络的目的是尽可能区分出一条序列是原始的还是生成的,问题在于股票本身的走势过于随机,想要直接区分出股票实际的走势和一条随机游走的序列之间可行性较低,除非生成网络生成的序列过于离谱。这里的结论是我个人的分析,并未实操过,感兴趣的话其实可以个人去尝试的。
如何划分数据集?¶
如何划分数据集,在其他的机器学习任务中可能也不应该成为一个需要讨论的问题,但是在量化领域,这个点还是值得单独拎出来讨论。常见的划分方法就是随机划分,sklearn中也提供了train_test_split这个函数来替我们完成这一操作。但是在量化中,可能存在以下的问题:
股票市场中是存在普涨或者普跌的现象的,如果这一天的4000只股票,有一半分到了训练集,另外一半在验证集,那么模型在学习了前2000只股票的样本后,在另外2000只的预测会存在比较高的准确率。但是实际上,这种上涨与下跌与股票本身的特征关系不大,更多地是市场性风险的一个反映,所以这个高的准确率,可能会有一定程度的虚高。
另外一点就是时间序列的连续性,受制于涨跌幅的限制,在加上股价本身变化一般不会特别大的特性,我们在使用一条时间序列进行训练后对相邻的时间序列预测时,也可能出现虚高的情况。比如训练集中的样本是T-100那一天的,标签的是T-99至T-89之间的走势,那么如果T-99的数据出现在验证集中,由于它的标签是T-98至T-88之间的走势,与训练集中的样本的重合多很高,所以就可能引发虚高的情况。
解决上述问题的一个简单的方法是按照时间去划分,并且保证训练集、验证集和测试集之间不存在时间重合,但是这可能导致近期的样本没有出现在训练集中,学习的范围不足,一个稍微优化的方式是在划分某个集的时候并不一定保证集合内部的时间连续性,可以将各个集合打散与其他集合在时间上形成穿插,并保证不存在重合区间,这样会在一定程度上丰富样本。
以上只是一个相对简单易行的方法,并不是完善的,实际使用也并不一定就比随机要好,但是本节最主要的目的就是让大家认识的时间序列预测相对于图像识别之类的特殊性,如何划分数据集是我们在做量化研究中需要加入到考量中的。
另一个需要注意的问题是样本的不均衡问题,这在时间序列的预测中也比较常见,笔者个人倾向于使用下采样,或者用不同采样的模型最终进行投票的方式,各位读者也可以在这方面做一定的研究和尝试。
使用Xgboost构建预测模型¶
在讨论完如何打标和数据集划分之后,剩下的问题其实反而比较简单,只需要调包来进行预测就可以了,以Xgboost为例,模型的使用并不复杂,在使用过程中并不需要重新设计模型的结构,只需要进行调参即可,而该模型是以决策树的机制为基础,因此对于数据的要求相对较低,使用过程中对于因子不需要特意调整到接近的区间内,并且对缺失值也不敏感,属于在实操中比较常用的一个模型。篇幅原因本文不对Xgboost的原理做过多的解释,感兴趣的读者可自行搜索。训练及评估的demo可以参考如下的写法:
训练部分:
测试集测试:
结语¶
关于使用机器学习来进行股价的预测,个人认为的重要性是打标>数据集划分>模型选择。另外一个必须关注的问题的就是,在量化领域,切记不要唯准确率论,大多是是,单单一个准确率并不完全挂钩于最终模型的实际效果,在模型的评估过程中,需要特别关注混淆矩阵,并且要对分类错误的样本在实际使用中的影响有一定的理解,例如,对于一个要下跌的股票,错误地预测成要上涨还是不涨不跌最终在投资过程中的影响程度是完全不同的,所以无论使用什么模型,采用怎样的分类方式,都要秉承着实际使用的价值和风险来对模型的效果进行全面的评估。
本篇的中最后是以Xgboost举例来说明的,这一模型可以看做非神经网络类模型的扛把子,读者也可以尝试使用类似的GBDT和LightGBM,或者其他类型的诸如随机森林的进行尝试。下一篇中我们将把模型聚焦到神经网络上,探究如何通过神经网络来取得更好的预测效果。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: 李浩然 华泰证券 算法工程师
来源: https://zhuanlan.zhihu.com/p/411348767