使用矢量空间AI NLP / NLU相关矩阵数据集生成阿尔法:股票与周期性¶
我最终击败了标准普尔500指数10%。这听起来可能不多,但当我们处理大量资本和良好的流动性时,对冲基金的利润是相当可观的。更激进的方法带来了更高的回报。
这一切都始于我读了古尔·胡伯曼(Gur Huberman)的一篇论文,题为"传染性投机和治愈癌症:使股价飙升的非事件"(与Tomer Regev合作,《金融杂志》,2001年2月,第56卷,第1期,第387-396页)。该研究描述了1998年与一家名为EntreMed的上市公司发生的事件(ENMD是当时的象征):
"周日《纽约时报》一篇关于新癌症治疗药物潜在开发的文章导致EntreMed的股价从周五收盘时的12.063上涨至85点,周一收于52点附近。在接下来的几周内,它收于30点以上。这种热情蔓延到其他生物技术股票。然而,癌症研究的潜在突破已经在 《自然》杂志和各种受欢迎的报纸上报道过,包括《泰晤士报》!五个多月前。因此,公众的热情关注导致股价永久上涨,尽管没有提出真正的新 信息 。
在研究者给出的许多有见地的观察中,其中有一个总结很突出:
「(股价)运动可能会集中于有一些共同之处的股票上,但这些共同之处不一定要是经济基础。」
我想知道是否有可能根据通常使用的东西以外的其他东西来对股票进行聚类。我开始四处寻找数据集,几周后我发现了一个数据集其中包括描述Vectorspace AI设计的元素周期表元素之间"已知和隐藏关系"强度的分数。
拥有计算基因组学的背景,这也让我想起了基因与其细胞信号网络之间的关系是多么的未知。然而,当我们分析数据时,我们开始看到新的联系和相关性,我们以前可能无法预测:
股票,就像基因一样,通过一个由彼此共享的强弱隐藏关系组成的庞大网络受到影响。其中一些影响和关系是可以预测的。
我的目标之一是创建多头和空头股票集群或"篮子聚类(basket clusters)",我可以用来对冲或只是从中获利。这将需要一种无监督的机器学习方法来创建股票集群,这些集群将彼此共享强弱关系。这些集群将兼作我公司可以交易的股票的"篮子(basket)"。
我首先 在这里下载数据集。数据集基于元素周期表中元素与上市公司之间的关系。将来,我想使用加密货币并创建类似于这些家伙 在这里 所做的篮子,但这是一个未来的项目。
然后我使用了 Python 和一些常用的机器学习工具——scikit-learn、numpy、pandas、matplotlib 和 seaborn,我开始了解我正在处理的数据集的分布形状(为了完成其中的一些工作,我查看了一个名为"使用KMeans视觉效果进行主成分分析"的Kaggle内核。
输出:前 5 行的快速视图:
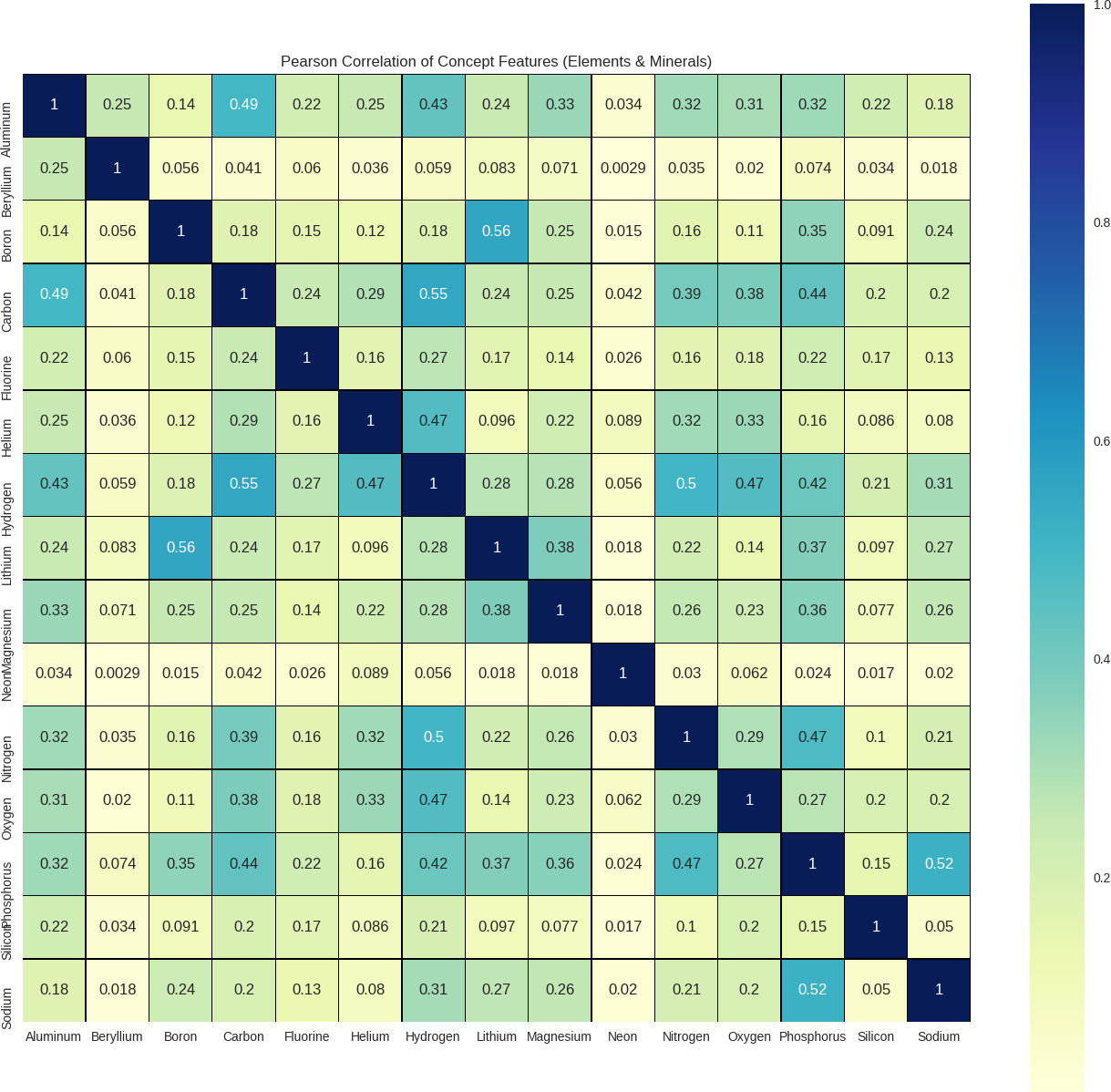
概念特征的皮尔逊相关性。在这种情况下,元素周期表中的矿物质和元素:
输出:(针对此可视化示例的前 16 个样本运行)。看看元素周期表中的元素如何与上市公司相关联也很有趣。在某些时候,我想使用这些数据来预测一家公司可能取得的突破,基于它们与有趣元素或材料的相关性。
测量"解释方差"和主成分分析(PCA)
解释方差 =(总方差 - 残差)。值得关注的PCA投影分量的数量可以由解释方差度量(Explained Variance Measure)来指导,这在Sebastian Raschka关于主成分分析的文章中也有很好的描述
输出:

从这张图表中,我们可以看到大量的方差来自预测主成分的前85%。这是一个很高的数字,所以让我们从低端开始,只为少数主成分建模。有关分析合理数量的主成分的更多信息,请 点击此处。
使用scikit-learn的PCA模块,让我们设置n_components = 9。代码的第二行调用fit_transform方法,该方法将 PCA 模型与标准化电影数据X_std拟合,并在此数据集上应用降维。
输出:
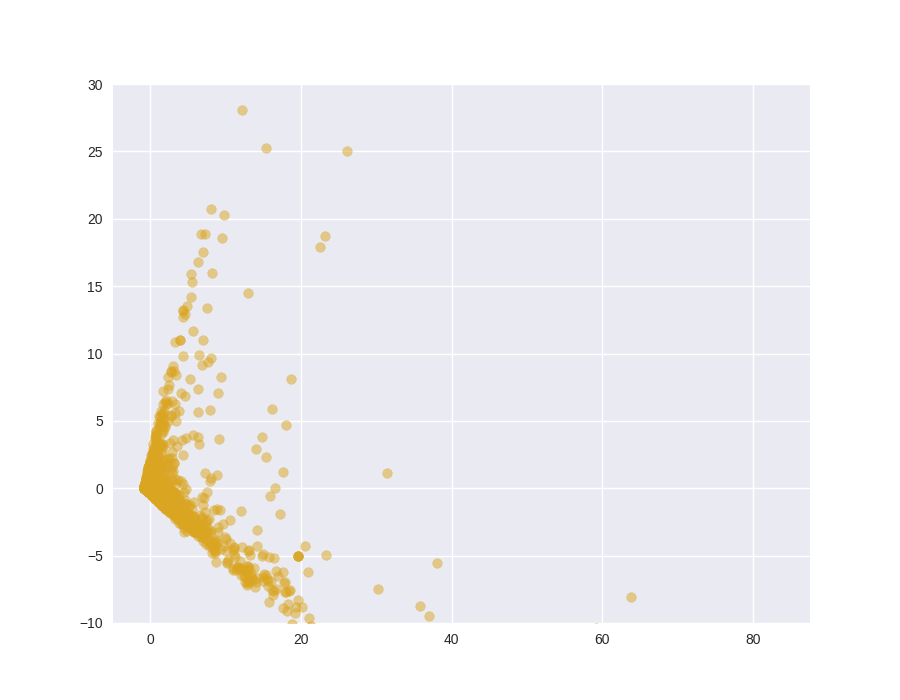
我们在这里甚至没有真正观察到集群的微弱轮廓,所以我们应该继续调整n_component值,直到我们看到我们喜欢的东西。这涉及数据科学和艺术的"艺术"部分。
现在,让我们尝试 K 均值,看看我们是否能够在下一节中可视化任何不同的聚类。
K 均值聚类
现在将使用PCA投影数据应用简单的K-Means。
输出:
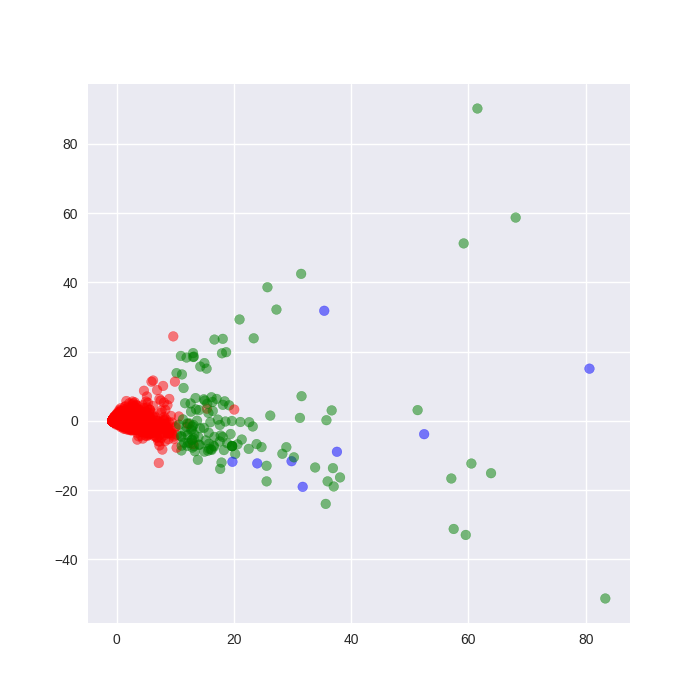
这个K-Means图现在看起来更有希望,就好像我们的简单聚类模型假设被证明是正确的一样,我们可以通过这种颜色可视化方案观察3个可区分的聚类。
当然,有许多不同的方法可以对数据集进行聚类和可视化,如下所示
使用 seaborn 方便的配对图函数,我可以成对方式自动绘制数据帧中的所有特征。我们可以将前 3 个投影相互配对并可视化:
输出:
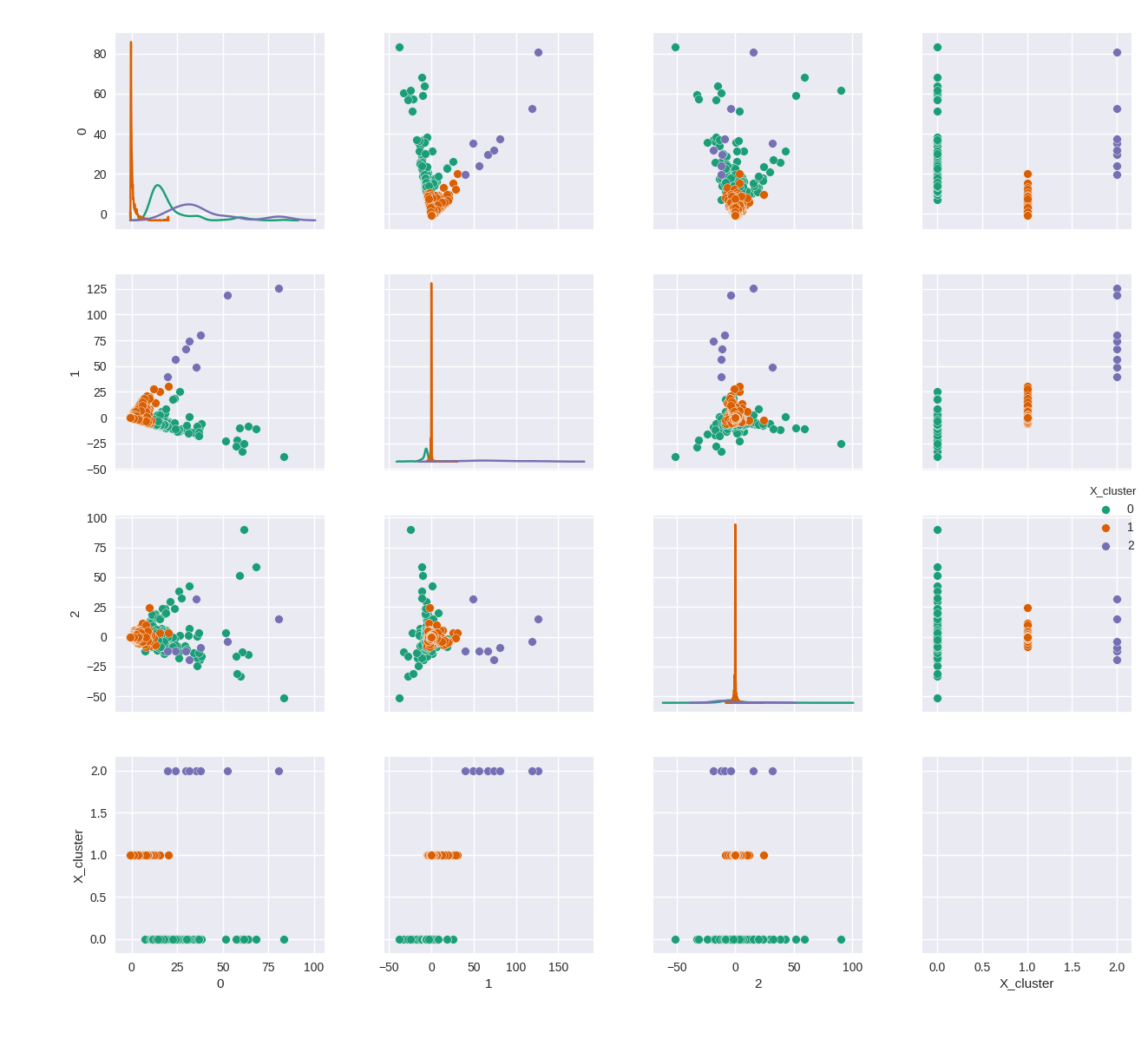
构建篮子聚类(Basket Clusters)
你应该自己决定如何微调你的聚类。这方面没有什么万灵药,具体的方法取决于你操作的环境。在这个案例中是由隐藏关系所定义的股票和金融市场。
一旦你的聚类使你满意了,你就可以设置分数阈值来控制特定的股票是否有资格进入一个聚类,然后你可以为一个给定的聚类提取股票,将它们作为篮子进行交易或使用这些篮子作为信号。你可以使用这种方法做的事情很大程度就看你自己的创造力以及你在使用深度学习变体来进行优化的水平,从而基于聚类或数据点的概念优化每个聚类的回报,比如 short interest 或 short float(公开市场中的可用股份)。 参考
你可以注意到了这些聚类被用作篮子交易的方式一些有趣特征。有时候标准普尔和一般市场会存在差异。这可以提供本质上基于「信息套利(information arbitrage)」的套利机会。某些聚类可能与 Google 搜索趋势相关。
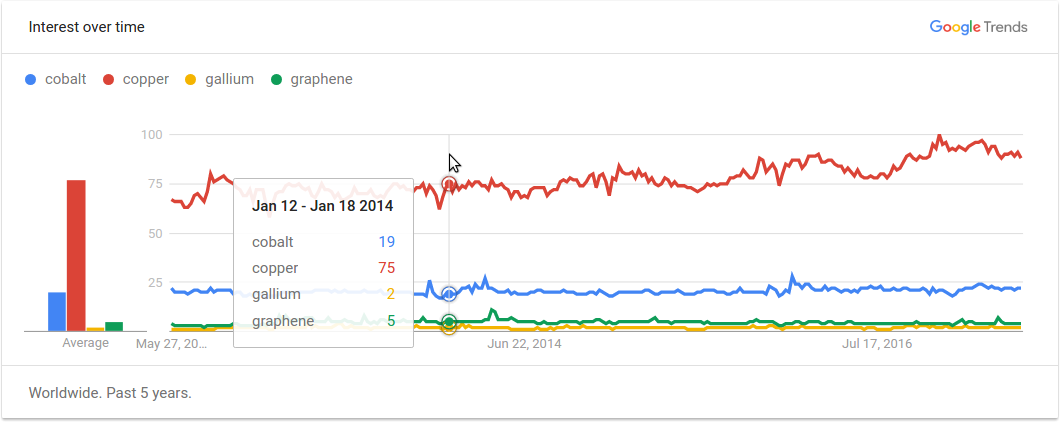
看到聚类和材料及它们的供应链相关确实很有意思,如本文所述:"放大10种材料及其供应链"。我仅仅使用该数据集操作了 Cobalt(钴)、Copper(铜)、Gallium(镓)和 Graphene(石墨烯)这几个列标签,只是为了看我是否可能发现从事这一领域或受到这一领域的风险的上市公司之间是否有任何隐藏的联系。这些篮子和标准普尔的回报进行了比较。
通过使用在 Quantopian, Numerai, Quandl 或Yahoo Finance等媒体上随时可用的历史价格数据,您可以汇总价格数据以生成使用 HighCharts可视化的预期回报:
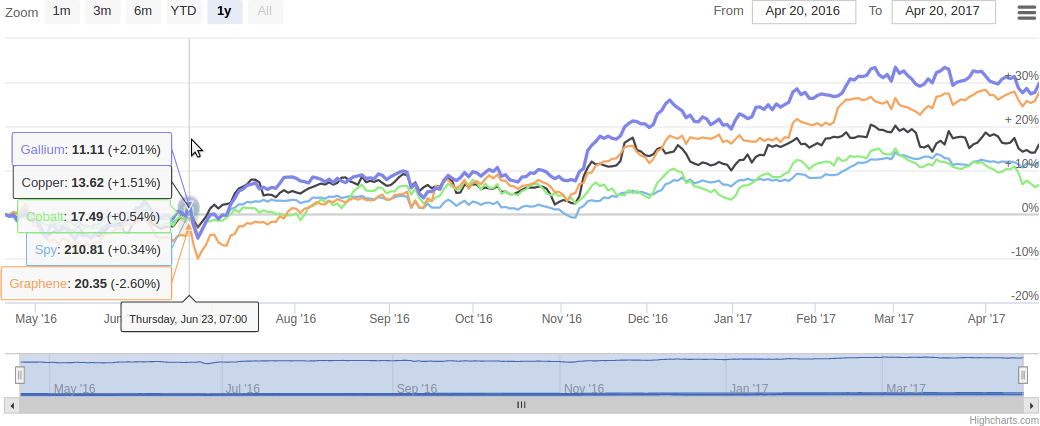
我从该聚类中获得的回报超过了标准普尔相当一部分,这意味着你每年的收益可以比标准普尔还多 10%(标准普尔近一年来的涨幅为 16%)。我还见过更加激进的方法可以净挣超过 70%。现在我必须承认我还做了一些其它的事情,但因为我工作的本质,我必须将那些事情保持黑箱。但从我目前观察到的情况来看,至少围绕这种方法探索和包装新的量化模型可以证明是非常值得的,而其唯一的缺点是它是一种不同类型的信号,你可以将其输入其它系统的流程中。
生成卖空篮子聚类(short basket clusters)可能比生成买空篮子聚类(long basket clusters)更有利可图。这种方法值得再写一篇文章,最好是在下一个黑天鹅事件之前。
如果你使用机器学习,就可能在具有已知和隐藏关系的上市公司的寄生、共生和共情关系之上抢占先机,这是很有趣而且可以盈利的。最后,一个人的盈利能力似乎完全关乎他在生成这些类别的数据时想出特征标签(即概念(concept))的强大组合的能力。
我在这类模型上的下一次迭代应该会包含一个用于自动生成特征组合或独特列表的单独算法。也许基于近乎实时的事件,这些事件可能会影响具有隐藏关系的股票组,只有配备无监督机器学习算法的人类才能预测。
作者:Gaëtan Rickter, — 财务数据顾问 — 日内瓦 瑞士
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: Gaëtan Rickter
来源: https://hackernoon.com/unsupervised-machine-learning-for-fun-profit-with-basket-clusters-17a1161e7aa1