加快Scikit-Learn训练¶
如果您的 scikit 学习模型需要一点时间来训练,那么您可以使用多种技术来提高处理效率。从优化模型配置到利用库,通过并行加速训练,您可以在最短的时间内构建出最好的 scikit 学习模型。
Scikit-Learning 是一个易于使用的 Python 计算机学习库。然而,有时学习的模型可能需要很长时间才能训练。问题是,如何在最短的时间内创建最佳的scikit学习模型?解决此问题的方法有很多,如:
这篇文章概述了每种方法,讨论了一些限制,并提供了资源,以加快您的机器学习工作流程!
更改优化算法(Solver)¶
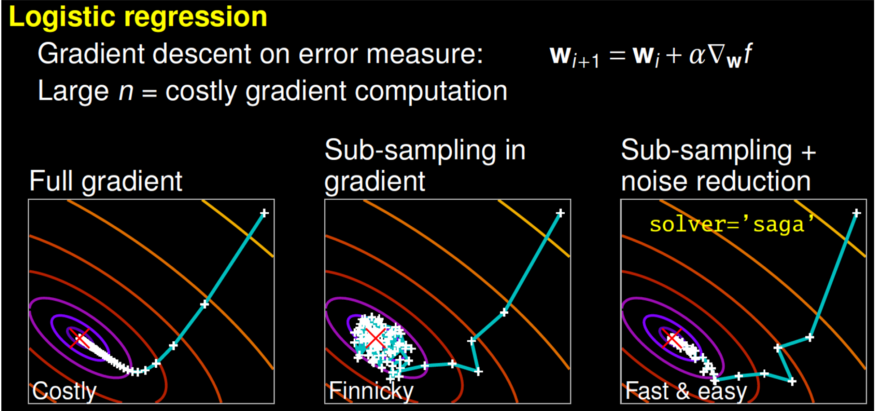
某些解解器可能需要更长的时间才能收敛。图片来自盖尔·瓦罗夸的演讲。
更好的算法允许您更好地使用相同的硬件。使用更高效的算法,您可以更快地生成最佳模型。这样做的一种方法是更改优化算法(解解器)。例如scikit-learn 的线性回归,允许您在newton-cg, lbfgs, liblinear, sag, saga等solver之间做出选择。
为了解不同的解算器是如何工作的,我鼓励你观看由 scikit-learn的核心贡献者盖尔·瓦罗夸的演讲。用他谈话的一部分来说,完整的渐变算法(libline)会迅速融合,但每次迭代(如图所示为白色 +)的成本可能高得令人望而却步,因为它需要您使用所有数据。在子示例方法中,每次迭代的计算成本低廉,但收敛速度要慢得多。一些算法,如saga,实现了两全其美。每次迭代计算成本低廉,由于方差缩小技术,算法会迅速融合。需要注意的是,快速收敛在实践中并不总是重要的,不同的解题器适合不同的问题。
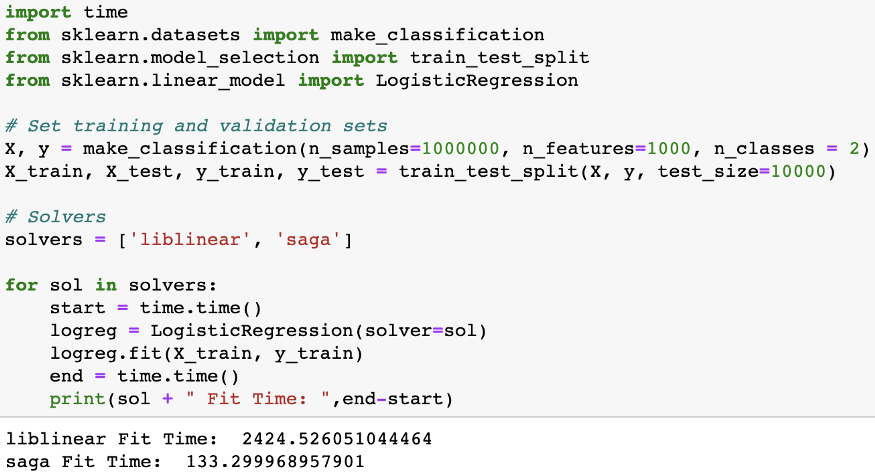
为问题选择正确的解答器可以节省大量时间(代码示例)。
要确定哪个解题器适合您的问题,您可以查看文档以了解更多。
不同的超参数优化技术(网格搜索、随机搜索、早期停止)¶
要实现大多数 scikit 学习算法的高性能,您需要调整模型的超参数。超参数是模型的参数,在训练期间未更新。它们可用于配置模型或训练功能。Scikit-Learn 本地包含几种超参数调谐技术,如网格搜索GridSearchCV这些技术详尽地考虑了所有参数组合和随机搜索RandomizedSearchCV后者从具有指定分布的参数空间中对给定数量的候选者进行采样。最近,scikit-learn添加了实验性超参数搜索估计器,称为减半网格搜索HalvingGridSearchCV和减半随机搜索HalvingRandomSearch)。
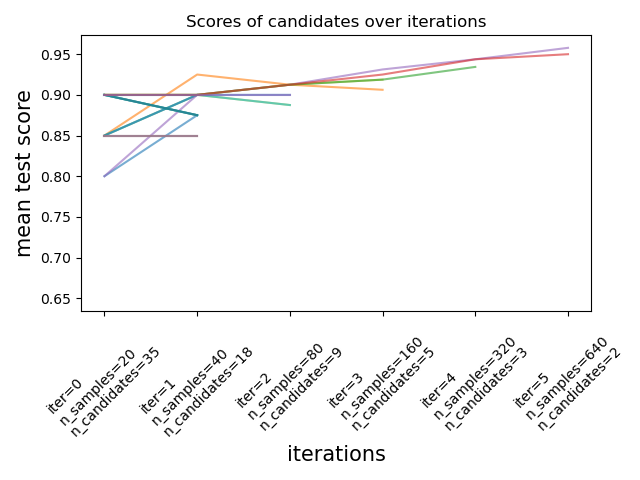
连续减半是 scikit 学习版本 0.24.1(2021 年 1 月)中的实验性新功能。来自文档的图像。
这些技术可用于使用连续减半来搜索参数空间。上图显示,在第一次迭代时,所有超参数候选人都用少量资源进行评估,在每次迭代中,选择更有前途的候选人并给予更多资源。
虽然这些新技术令人兴奋,但有一个名为Tune-sklearn库,提供尖端的超参数调谐技术(Bayesian 优化、早期停止和分布式执行),可通过网格搜索和随机搜索提供显著的加速速度。
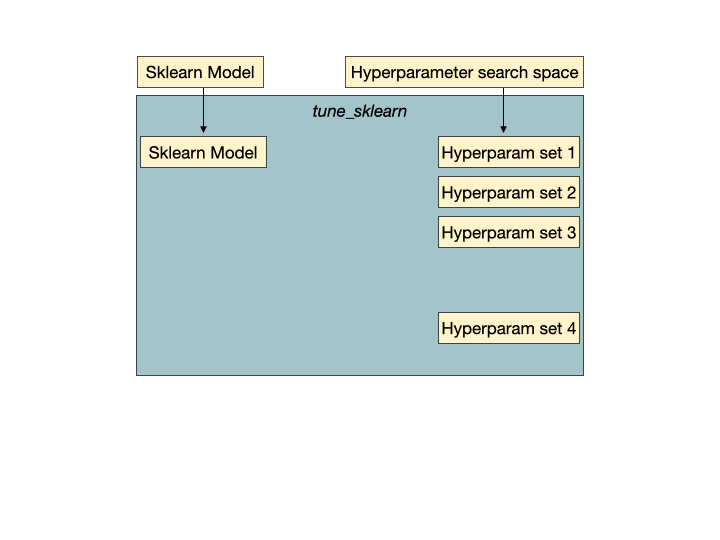
提前停止行动。Hyperparameter set 2 是一组无希望的超参数,通过 Tune-sklearn 的早期停止机制检测,并提前停止,以避免浪费时间和资源。图像来自GridSearchCV 2.0
Tune-sklearn 包括:
- 与 scikit 学习 API 的一致性:您通常只需要更改几行代码来使用 Tune-sk 学习(例如)。
- 可访问现代超参数调谐技术:很容易更改代码,以利用贝叶斯优化、早期停止和分布式执行等技术。
- 框架支持:不仅有支持scikit学习模型,但其他scikit-learn wrappers,如Skorch (PyTorch)KerasClassifiers (Keras)和XGBoostClassifiers (XGBoost)
- 可扩展性:该库利用用于分布式超参数调谐的库Ray Tune在多个内核甚至多个机器上高效、透明地并行交叉验证。
也许最重要的是,tune-sklearn速度很快,如下图所示。
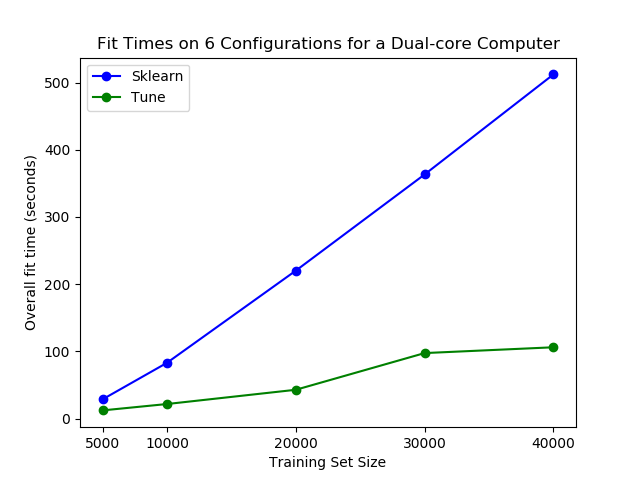
使用tune-sklearn,您可以在普通笔记本电脑上看到显著的性能差异。图像来自GridSearchCV 2.0
如果你想了解更多关于调子学习,你应该看看这个博客文章。
使用joblib、Ray 并行或分发¶
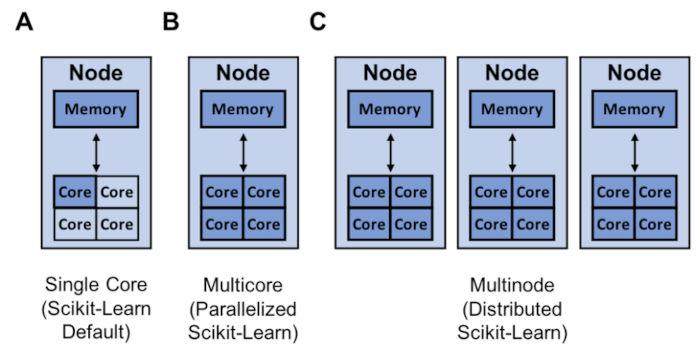
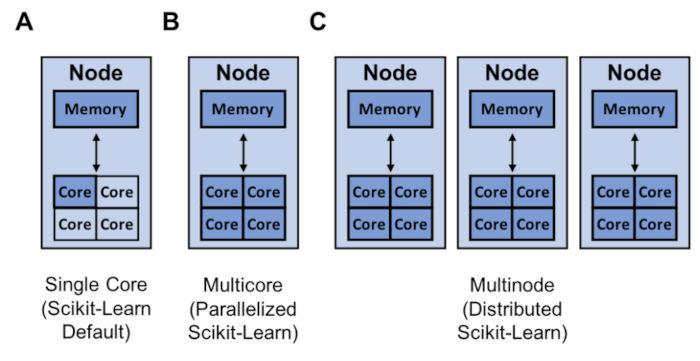
scikit-学习的资源(深蓝色)可用于单核(A)、多核(B)和多节点训练(C)。
提高模型构建速度的另一种方法是将您的训练与joblib和Ray平行或分发。默认情况下,scikit 学习使用单个内核训练模型。需要注意的是,如今几乎所有计算机都有多个内核。
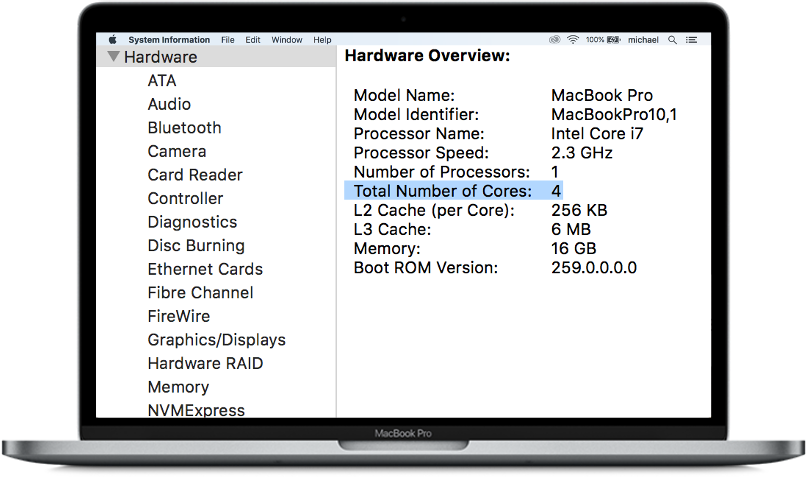
对于此博客的目的,您可以将上面的 MacBook 视为具有 4 个内核的单个节点。
因此,有很多机会通过利用计算机上的所有内核来加快模型的训练。如果您的模型具有高度的并行性,如随机决策森林,则尤其如此。
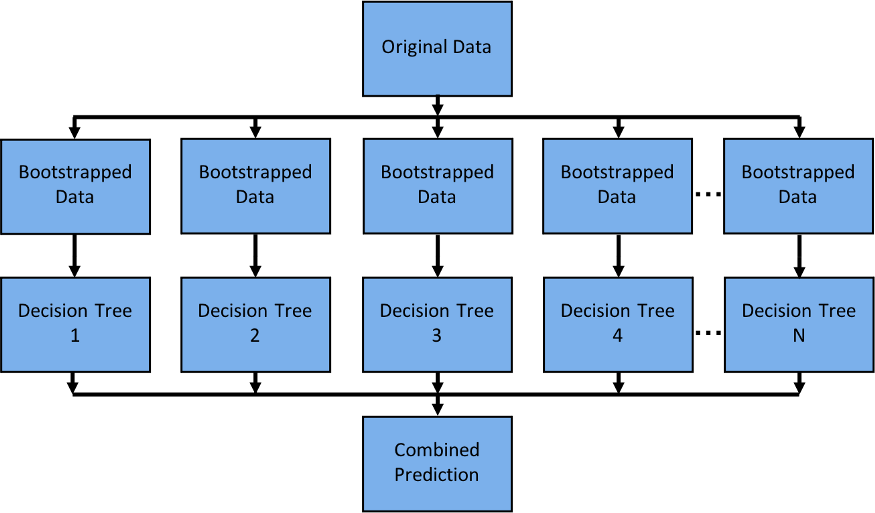
随机决策森林是一种简单的模型,可平行,因为每个决策树都独立于其他决策树。
Scikit-Learn 可以在单个节点上与joblib平行训练,默认情况下,该节点使用loky backend。Joblib 允许您在后端(如"loky"、"multiprocessing"、"dask"和"ray")之间进行选择。这是一个伟大的功能,因为"loky"后端是针对单个节点进行优化的,而不是用于运行分布式(多节点)应用程序。运行分布式应用程序可以引入许多复杂性,如:
- 跨多台机器安排任务。
- 高效传输数据。
- 从机器故障中恢复。
幸运的是,ray可以为您处理这些细节,保持简单,并给你更好的性能。下图显示了 Ray、多处理和 Dask 相对于默认的"loky"后端的执行时间的规范化加速。

性能测量在一个,五个和十m5.8x大节点,每个32个内核。Loky 和多处理的性能不取决于机器的数量,因为它们在单台机器上运行。图像源。
如果你想了解如何快速平行或分发你的scikit学习训练,你可以看看这个博客文章。
结论¶
这篇文章通过几种方式,你可以建立最好的scikit学习模型可能在最短的时间内。有一些方法是原产于scikit学习,如改变你的优化功能(解压器)或通过使用实验性超参数优化技术,如HalvingGridSearchCV或HalvingRandomSearch。也有库,你可以用作插件,如Tune-sklearn和ray,以进一步加快您的模型建设。如果您对 Tune-sklearn 和 Ray 有任何疑问或想法,请随时通过Discourse 或Slack加入我们的社区。
相关:
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: Michael Galarnyk
来源: https://www.kdnuggets.com/2021/03/speed-up-scikit-learn-model-training.html