特征选择: 如何丢掉95%的数据并获得95%的准确率¶
特征选择是数据管道中的一个基本步骤。举个例子, 在MNIST数据集上,你只需要40个像素(在784个像素中)就能获得95%以上的准确性(99%的ROC)。
1. 为什么要进行特征选择?¶
你能识别这些手写的数字吗?

去除75%的图像后的一些MNIST数字。
你可能不难发现,这些数字分别是一个0、一个3和一个8。 如果是这样的话,即使只有25%的原始图像被显示出来,而剩下的75%被红色像素所覆盖,你也能对它们进行正确分类。这是一项简单的任务,因为 "相关 "的像素是可见的,而只有 "不相关 "和 "多余 "的像素被隐藏了。
这是一个 "特征选择 "的简单例子。
特征选择是机器学习中进行的一个过程,在将数据输入预测模型之前,一些特征被删除。如果你的数据是以表格的形式存在,这仅仅意味着从你的表格中去掉许多列。
实际上,有几个原因,你可能想做特征选择。
- 内存。大数据需要很大的空间。抛弃特征意味着你需要更少的内存来处理你的数据。有时也有外部约束(例如,谷歌的AutoML允许你使用不超过1000个列。因此,如果你有超过1,000个列,你将被迫只保留其中的一部分)
- 时间。在较少的数据上训练一个模型可以为你节省很多时间。
- 准确度。少即是多:这也适用于机器学习。包括多余的或不相关的特征意味着包括不必要的噪音。经常发生的情况是,在较少的数据上训练的模型表现得更好。
- 可解释性。一个较小的模型意味着一个更容易解释的模型。想象一下,如果你不得不解释一个基于数千个不同因素的模型:这将是不可行的。
- 调试。一个较小的模型更容易维护和排除故障。
2. 从数据开始¶
在这篇文章中,我们将比较一些特征选择的方法。我们的数据集将是世界闻名的 "MNIST"。
MNIST是一个由70000张手写数字的黑白图像组成的数据集。每张图像是28 x 28(= 784)像素。每个像素被编码为从1(白色)到255(黑色)的整数:这个值越高,颜色越深。按照惯例,60,000张图片作为训练集,10,000张作为测试集。
这些数据可以通过Keras命令导入到Python中(我们还将重塑数据集,使其成为二维的,作为一个表格)。
例如,让我们打印出第8行的数值。
这就是结果。

MNIST训练数据集的第8幅图像的所有784个像素
通过Matplotlib,我们还可以显示相应的图像。

MNIST训练数据集的第8张图片
3. 特征选择之战¶
有许多可能的策略和算法来执行功能选择。在本文中,我们将对其中6个进行测试:
我们的任务是选择少量的列(即像素),这些列在输入预测模型时足以达到良好的准确度。有许多可能的策略和算法来进行特征选择。在本文中,我们将对其中的6种进行测试。
3.1 F-Statistic¶
F-Statistic是方差分析F检验的结果。这个测试的计算方法是:组间变异性/组内变异性的比率,其中组是目标类别。
我们的想法是,当组间(0类图像、1类图像、......、9类图像)的变异性较高而同一组内的变异性较低时,一个像素是相关的。
3.2 相互信息¶
相互信息是对两个变量之间相互依赖的衡量。
由于MI的公式需要知道每个变量的概率分布(而通常我们不知道分布),scikit-learn的实现采用了基于k-近邻距离的非参数近似。
3.3 Logistic Regression¶
如果目标变量是分类的(如我们的案例),可以对数据进行Logistic回归。然后,可以用特征的相对重要性将它们从最相关排到最不相关。
3.4 LightGBM¶
任何预测模型都可以做到这一点。例如,LightGBM。
3.5 Boruta¶
Boruta是一个优雅的算法,于2010年作为R的一个包而设计。Boruta的目的是告诉每个特征是否与目标变量有某种关系。因此,Boruta的输出更多的是每个特征的是/否,而不是一个特征的排名。
3.6 MRMR¶
MRMR(代表 "最大相关度最小冗余")是2005年设计的一种特征选择算法。MRMR背后的想法是确定一个特征子集,这个子集与目标变量有很高的相关性,并且相互之间的冗余度很小。
所有这些算法都提供了一个特征的 "排名"(除了Boruta,它有一个是/否的结果)。让我们看看不同算法的排名如何变化。
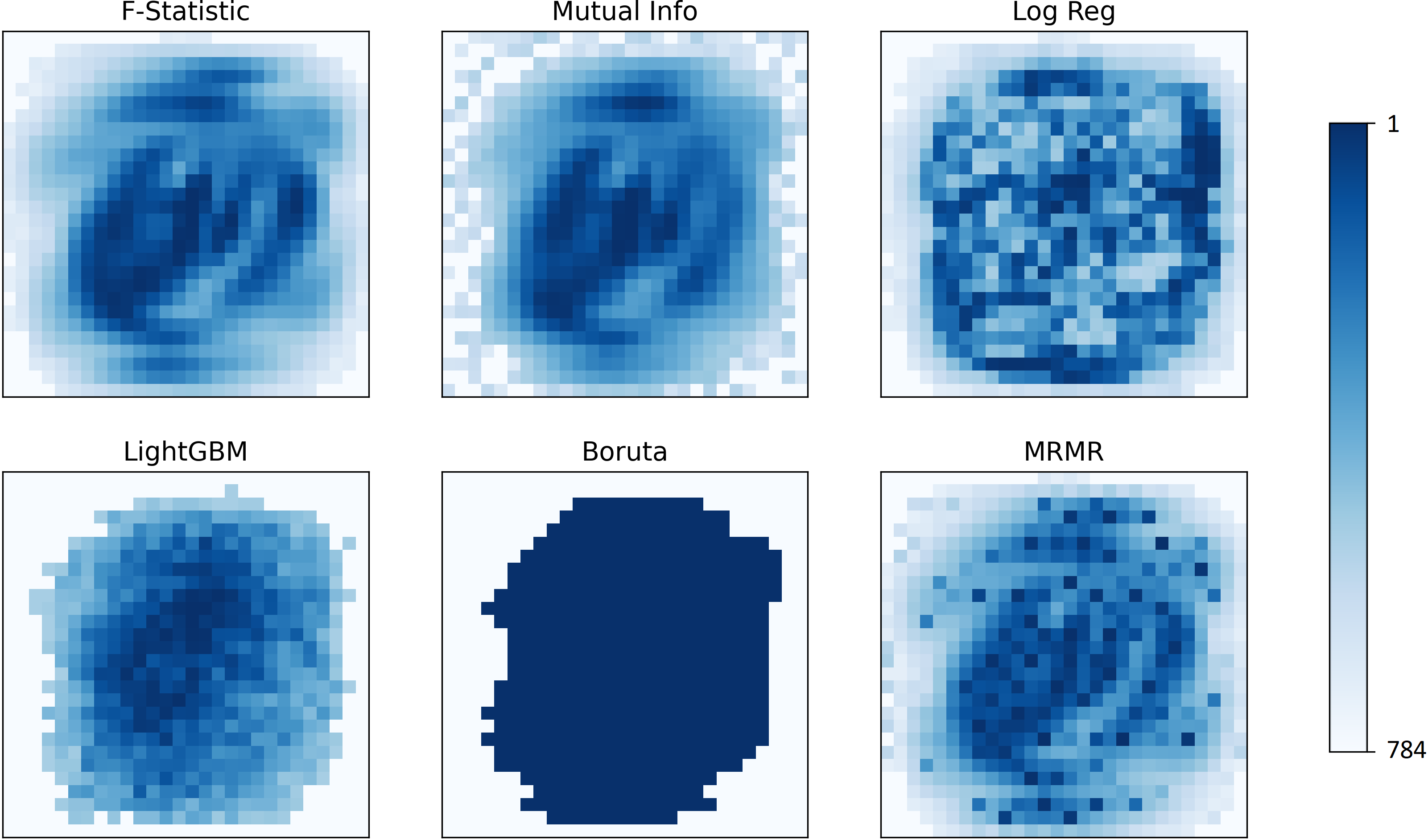
MNIST。根据不同的算法,像素按其相关性进行排名。
4. 哪种方法效果更好?¶
在这一点上,一个自然的问题是。
我应该选择什么方法进行特征选择?
与数据科学中的一贯做法一样,最好的选择是测试不同的方法,看看哪种方法在你的数据上能得到更好的结果。因此,让我们在MNIST上试试。
我们将采用5种方法提供的特征排名(因为Boruta不提供排名),看看在前K个特征上训练预测模型时能达到什么准确度(对于K最多40个)。
这些是结果:

在这种情况下,MRMR的表现超过了其他算法。 如图所示,在MRMR识别的最相关的40个像素上训练的预测器在测试图像上达到了95.54%的准确率!这让人印象深刻。
这是相当令人印象深刻的,特别是如果我们考虑到。
- 40个像素只占整个图像的5%(由28 x 28 = 784个像素组成)。
- 我们使用了一个没有进一步调整的预测模型(CatBoost),因此这个性能可能会进一步提高。
因此,在 MNIST 的情况下, 我们可以扔掉 95% 的数据,并且仍然获得超过 95% 的准确性(这相当于 ROC 下 99.85% 的区域!
即使 MNIST 是一个"简单"的数据集,其主要启示对大多数现实世界的数据集都是有效的。通常情况下, 只需一小部分功能即可实现高精度。有效的特征选择可以使你建立的数据管道在内存、时间、准确性、可解释性和易调试性方面更有效率 。
谢谢你的阅读! 我希望你觉得这篇文章有用。
本文显示的结果完全可以通过这段代码重现:Github。
我感谢反馈和建设性的批评。如果你想讨论这篇文章或其他相关话题,你可以发短信给我的Linkedin。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: Samuele Mazzanti
来源: https://towardsdatascience.com/feature-selection-how-to-throw-away-95-of-your-data-and-get-95-accuracy-ad41ca016877