可视化 100,000 亚马逊产品¶
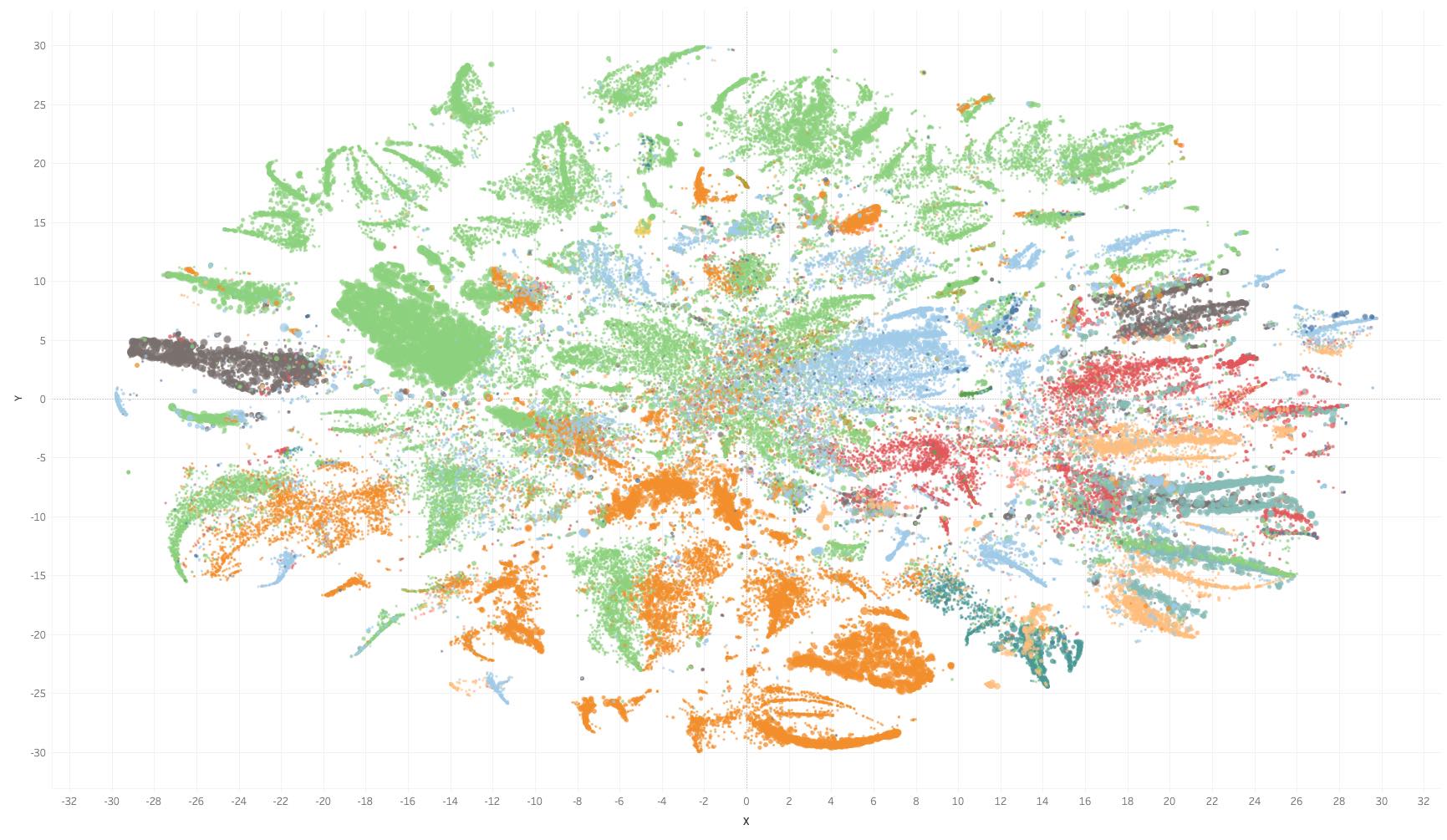 100,000种Amazon产品的t-SNE映射
100,000种Amazon产品的t-SNE映射
本文中的fse代码可能已被弃用。请确保使用github 上概述的更新代码。 Juniper notebook
pip install -U fse
您将需要常规的Python(> 3.6)软件包,特别是Numpy,Scipy,Cython和Gensim。 TL; DR:如果需要快速嵌入句子,请使用:
这篇文章面向技术数据科学的读者。我们将探索如何使用快速句子嵌入来可视化著名的Amazon评论数据集。此故事中使用的工具是fse,FIt -SNE和Tableau。您将在本文末尾找到指向交互式Tableau映射的链接,以浏览所有100,000个产品。 有关库的内部工作原理的详细介绍,请随时阅读我的第一篇有关句子嵌入的medium文章。
数据¶
如果您从事NLP,那么您可能会从公开的Stanford Amazon评论数据集得到。三年前,我已经获得了朱利安·麦考利(Julian McAuley)的完整版,供我在市场营销方面的博士研究之用,并且确实会不时地继续使用它。第二大类别是“电子”类别,共有7,824,482条评论。知道里面到底有什么不是很好吗?
为了获得每个产品的嵌入,我们需要评论数据和元数据。两者都通过唯一的Amazon ASIN标识符连接。我已经将所有内容准备为一个不错的Pandas DataFrame(不允许共享)。让我们看一下元数据:
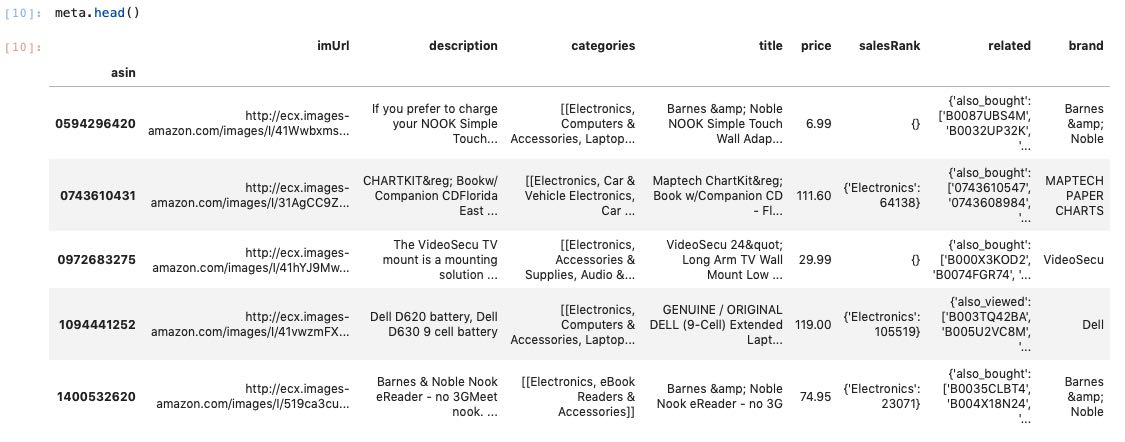
要实际可视化数据(即将每个产品表示为可对比的矢量),我们只能使用每个产品的评论。因此,我们正在应对多对一嵌入。在过滤掉不到 10 条评论的 ASIN 后,我们最终会得到 97,249 条独特的 ASIN 和 6,875,530 条评论。
我们不执行任何文本数据的预处理。
为什么?
从审查到产品嵌入¶
要获得每次审查的嵌入,我们首先需要某种预先训练的嵌入。评论可能包含许多未知词。幸运的是 fse 为开箱即用的 FastText 模型提供支持。我们首先加载公开的 FastText 模型:
接下来,我们将 SIF 模型从 fse 中 实化。
组件数量等于 10 个,STS 基准 可重复性 部分报告了这一数目。
请注意lang_freq参数。某些预先训练的嵌入在语料库中不包含有关单词频率的信息。 fse 支持为多种语言的预先培训的模型引入单词频率,这对 SIF 和 uSIF 模型至关重要(这可能需要一段时间,具体取决于您的词汇量)。
所有 fse 模型都要求输入为大块头列表。图集的第一个条目是代币列表(句子),第二个条目表示句子的索引。后者确定添加句子的嵌入矩阵中的目标行。我们稍后会在一行(多行)上写多个句子(评论)。
fse 提供了多个输入类,所有这些类都提供了不同的功能。有6个输入类可以选择:
- IndexedList:用于已预拆分的句子。
- CIndexedList:用于已预拆分的句子,每个句子都有自定义索引。
- SplitIndexedList:对于尚未拆分的句子。将分割字符串。
- SplitCIndexedList:用于未拆分的句子,并为每个句子使用自定义索引。
- CSplitIndexedList:对于尚未拆分的句子。将分割字符串。您可以提供自定义拆分功能。
- CSplitCIndexedList:用于要提供自定义索引和自定义拆分功能的句子。
- IndexedLineDocument:用于从磁盘流式传输句子。是可索引的,以方便搜索类似的句子。
这些是按速度排列的。IndexedList是最快的,而 CSplitCIndexedList是最慢的变体(更多的调用=较慢)。为什么要分这么多类?因为我想让每个__getitem__方法尽可能少地使用代码行,而不是减慢计算速度。
对于我们的审查数据,我们使用的是SplitCIndexedList,因为我们不想预先拆分数据(预拆分 7M. 评论占用了大量内存)。在内部,该类将指向我们的评论,并且仅在您调用__getitem__时执行预处理。
请注意,这两个句子都指向索引 0。因此,它们都将添加到嵌入索引 0 中。要将每个 ASIN 映射到索引,我们只需要一些进一步的便利功能。
既然我们已经准备好了一切,我们可以调用
该模型在云实例上进行了培训,具有 16 个内核和 32 GB RAM。整个过程大约需要 15分钟 ,约8500评论/秒。每篇评论平均包含 86 个单词,总共遇到 593,774,622 个单词。我们将大约 700 万条评论压缩为形状为 100,000 * 300 的矩阵。增加更多的工人没有区别,因为预处理(拆分)是瓶颈。
如果您的数据已经预先分割,您可以在常规 MacBook Pro 上达到 500,000 句/秒。如果你想了解更多,请查看教程 笔记本 。
使用和可视化嵌入¶
培训句子嵌入后,我们可以访问由其索引或完整嵌入矩阵嵌入的每一个人。该语法尽可能接近 Gensims 语法,便于使用。
相应的句子研究者 (sv) 类提供了相当多的函数来处理由此产生的句子嵌入。例如,您可以使用相似性、距离、most_similar、similar_by_word、similar_by_sentence或similar_by_vector。
如果我们恢复到标准的sk学习t-SNE实现,可视化这么多数据可能需要很长时间。因此,让我们尝试一种更优化的方法 FIt-SNE这种优化的 t-SNE 实现利用傅立体转换来加快 t-SNE 的计算速度。随意阅读论文[4]。它的工作原理就像一个魅力,并使用机器的所有16个核心。
计算完映射后,我们有效地完成了最困难的部分。将元数据中的一些信息添加到每个点,我们最终可以将所有信息导出到 Tableau。
表图映射¶
要访问相应的图形,请访问我的公共 tableau 页面
您可以在每一点上徘徊,获取有关产品价格、名称、品牌等的信息。
查看嵌入,我们发现每个聚类中包含相当多的信息。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: Dr. Oliver Borchers
来源: https://towardsdatascience.com/vis-amz-83dea6fcb059