使用 Python 和 spaCy 进行信息提取简介
介绍
作为数据科学家,我非常依赖搜索引擎(尤其是谷歌)。我的搜索结果涵盖了各种查询 - Python代码问题,机器学习算法, 自然语言处理(NLP)框架的比较等。
我一直很好奇这些搜索引擎如何理解我的查询并提取相关结果,就好像他们知道我在想什么一样。
我想了解 NLP 方面在这里是如何工作的 - 基本上,算法如何理解非结构化文本数据并将其转换为结构化数据并向我显示相关结果?
注意:我建议阅读这篇关于 数据科学中的计算语言学和依赖关系树简介 的文章,以便更好地了解我们将在这里学到的内容。
目录
- 信息提取简介
- 语义关系:从非结构化文本中获取结构化知识
- 不同的信息提取方法
- 使用Python和spaCy进行信息提取
- spaCy 基于规则的匹配
- 用于关系提取的子树匹配
- 下一步是什么?
信息提取简介
信息提取(IE)是自然语言处理(NLP)和语言学领域的关键齿轮。它广泛用于问答系统, 机器翻译,实体提取,事件提取,命名实体链接,共指解析,关系提取等任务。
在信息提取中,有一个重要的 三元 组概念。
三元组表示几个实体以及它们之间的关系。例如,(奥巴马,出生,夏威夷)是一个三重,其中“奥巴马”和“夏威夷”是相关实体,它们之间的关系是“出生”。
在本文中,我们将重点介绍从给定文本中提取这些类型的三元组。
在继续之前,让我们看一下信息提取的不同方法。我们可以大致将信息提取分为两个分支,如下所示:
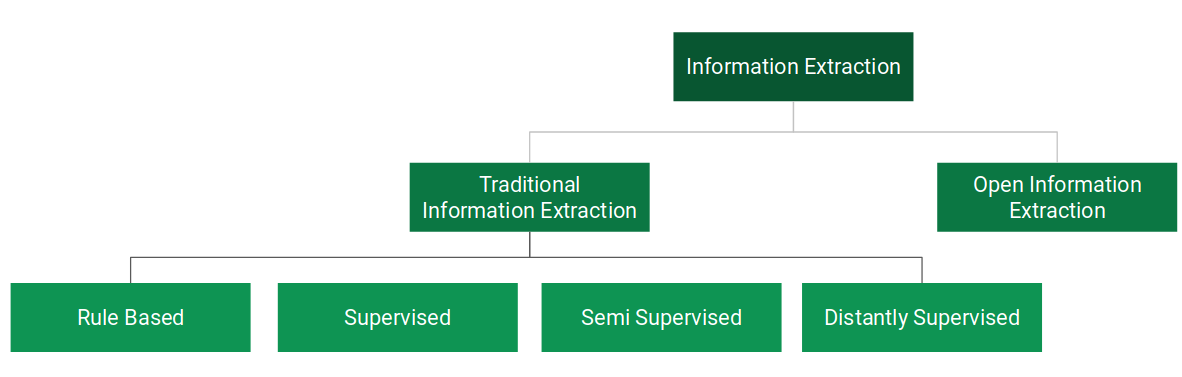
在 传统信息提取 中,要提取的关系是预定义的。在本文中,我们将仅介绍基于规则的方法。
在 开放信息提取 中,关系不是预定义的。系统可以自由地提取在浏览文本数据时遇到的任何关系。
语义关系:从非结构化文本中获取结构化知识
看看下面的文本片段:

你能想到任何方法从这段文字中提取有意义的信息吗?让我们尝试逐句解决这个问题:

在第一句话中,我们有两个实体(“Food Tutorials”和“Wes Anderson”)。这些实体通过术语“directed”相关联。因此,(Wes Anderson,directed,Food Tutorials)是三元组。同样,我们也可以从其他句子中提取关系:

事实证明,我们可以根据文本的句法结构和语法获得结构化信息,如上面的示例所示。
不同的信息提取方法
在上一节中,我们设法轻松地从几个句子中提取了三元组。然而,在现实世界中,数据规模巨大,手动提取结构化信息是不可行的。因此,自动化这种信息提取变得很重要。
有多种方法可以自动执行信息提取。让我们一一了解它们:
- 基于规则的方法: 我们为自然语言的语法和其他语法属性定义了一组规则,然后使用这些规则从文本中提取信息。
- 监督 :假设我们有一个句子S。它有两个实体 E1 和 E2。现在,监督式机器学习模型必须检测 E1 和 E2 之间是否存在任何关系 (R)。因此, 在监督方法中,关系提取的任务变成了关系检测的任务。 这种方法的唯一缺点是它需要大量的标记数据来训练模型。
- 半监督 :当我们没有足够的标记数据时,我们可以使用一组种子示例(三元组)来制定高精度模式,这些模式可用于从文本中提取更多关系
使用Python和spaCy进行信息提取
我们已经掌握了这里的理论,所以让我们进入Python代码方面。
我们将做一个小项目,从非结构化数据(在我们的例子中是文本数据)中提取结构化信息。我们已经看到,文本中的信息以不同实体之间的关系形式存在。
因此,在本节中,我们将尝试发现和提取与某种关系或另一种关系关联的不同实体对。
在我们开始之前,让我们谈谈Marti Hearst。她是加州大学伯克利分校信息学院的计算语言学研究员和教授。Marti教授实际上已经对信息提取这一主题进行了广泛的研究。她最有趣的研究之一集中在建立一组文本模式上,这些模式可以用来从文本中提取有意义的信息。 这些模式通常被称为“Hearst Patterns”。
让我们看一下下面的例子:

我们可以通过观察句子的结构来推断“Gelidium”是一种“red algae”(红藻)。在语言学术语中,我们将“红藻”称为上位词(Hypernym),将“Gelidium”称为其下位词(Hyperonym)。
我们可以将这种模式形式化为“X,如Y”,其中 X 是上位词,Y 是下位词。这是Hearst Patterns的众多模式之一。这里有一个列表,让你对这个想法有一个直觉:

现在让我们尝试使用这些模式/规则来提取上位词-下位词对。我们将使用 spaCy 的基于规则的匹配器来执行此任务
首先,我们将导入所需的库
| import re
import string
import nltk
import spacy
import pandas as pd
import numpy as np
import math
from tqdm import tqdm
from spacy.matcher import Matcher
from spacy.tokens import Span
from spacy import displacy
pd.set_option('display.max_colwidth', 200)
|
接下来,加载一个 spaCy 模型[Gist]
| # load spaCy model
nlp = spacy.load("en_core_web_sm")
|
我们都准备根据这些赫斯特模式从文本中挖掘信息。
模式:X 如 Y
| # sample text
text = "GDP in developing countries such as Vietnam will continue growing at a high rate."
# create a spaCy object
doc = nlp(text)
|
为了能够从上面的句子中提取所需的信息,理解它的句法结构非常重要——比如句子中的主语、宾语、修饰语和词性 (POS)。
我们可以使用 spaCy 轻松探索句子中的这些句法细节:
| # print token, dependency, POS tag
for tok in doc:
print(tok.text, "-->",tok.dep_,"-->", tok.pos_)
|
输出:
| GDP --> nsubj --> NOUN
in --> prep --> ADP
developing --> amod --> VERB
countries --> pobj --> NOUN
such --> amod --> ADJ
as --> prep --> ADP
Vietnam --> pobj --> PROPN
will --> aux --> VERB
continue --> ROOT --> VERB
growing --> xcomp --> VERB
at --> prep --> ADP
a --> det --> DET
high --> amod --> ADJ
rate --> pobj --> NOUN
. --> punct --> PUNCT
|
看看术语“such”和“as”。它们后跟一个名词(“国家”)。在它们之后,我们有一个专有名词(“越南”)作为下位词。
因此,让我们使用依赖标签和 POS 标签创建所需的模式:
| #define the pattern
pattern = [{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'} #proper noun]
|
让我们从文本中提取模式:
| # Matcher class object
matcher = Matcher(nlp.vocab)
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
输出: “越南等国家”(‘countries such as Vietnam’)
好!它完美地工作。但是,如果我们能得到“developing countries”而不仅仅是“countries””,那么产出就会更有意义。
因此,我们现在还将使用以下代码捕获名词在“such as”之前的修饰符:
| # Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"}, # adjectival modifier
{'POS':'NOUN'},
{'LOWER': 'such'},
{'LOWER': 'as'},
{'POS': 'PROPN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
输出: “developing countries such as Vietnam”
在这里,“developing countries”是上位词,“越南”是下位词。它们都是语义相关的。
注意:上述模式中的键“OP”:“?”表示修饰符(“amod”)可以出现一次,也可以根本不出现。
以类似的方式,我们可以从任何一段文本中获得几对:
- Fruits such as apples
- Cars such as Ferrari
- Flowers such as rose
现在,让我们使用其他一些赫斯特模式来提取更多的上位词和下位词。
模式:X 和/或 Y
| doc = nlp("Here is how you can keep your car and other vehicles clean.")
# print dependency tags and POS tags
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
|
输出:
| Here --> advmod --> ADV
is --> ROOT --> VERB
how --> advmod --> ADV
you --> nsubj --> PRON
can --> aux --> VERB
keep --> ccomp --> VERB
your --> poss --> DET
car --> dobj --> NOUN
and --> cc --> CCONJ
other --> amod --> ADJ
vehicles --> conj --> NOUN
clean --> oprd --> ADJ
. --> punct --> PUNCT
|
| # Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
输出: “car and other vehicles”
让我们尝试使用相同的代码来捕获“X或Y”模式:
| # replaced 'and' with 'or'
doc = nlp("Here is how you can keep your car or other vehicles clean.")
|
代码的其余部分将保持不变:
| # Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'amod', 'OP':"?"},
{'POS':'NOUN'},
{'LOWER': 'and', 'OP':"?"},
{'LOWER': 'or', 'OP':"?"},
{'LOWER': 'other'},
{'POS': 'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
输出: “car or other vehicles”
模式:X,包括 Y
| doc = nlp("Eight people, including two children, were injured in the explosion")
for tok in doc:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
|
输出:
| Eight --> nummod --> NUM
people --> nsubjpass --> NOUN
, --> punct --> PUNCT
including --> prep --> VERB
two --> nummod --> NUM
children --> pobj --> NOUN
, --> punct --> PUNCT
were --> auxpass --> VERB
injured --> ROOT --> VERB
in --> prep --> ADP
the --> det --> DET
explosion --> pobj --> NOUN
|
| # Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'nummod','OP':"?"}, # numeric modifier
{'DEP':'amod','OP':"?"}, # adjectival modifier
{'POS':'NOUN'},
{'IS_PUNCT': True},
{'LOWER': 'including'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
输出: “Eight people, including two children”
模式:X,尤其是 Y
| doc = nlp("A healthy eating pattern includes fruits, especially whole fruits.")
for tok in doc:
print(tok.text, tok.dep_, tok.pos_)
|
输出:
| A --> det --> DET
healthy --> amod --> ADJ
eating --> compound --> NOUN
pattern --> nsubj --> NOUN
includes --> ROOT --> VERB
fruits --> dobj --> NOUN
, --> punct --> PUNCT
especially --> advmod --> ADV
whole --> amod --> ADJ
fruits --> appos --> NOUN
. --> punct --> PUNCT
|
输出: “fruits, especially whole fruits”
| # Matcher class object
matcher = Matcher(nlp.vocab)
#define the pattern
pattern = [{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'},
{'IS_PUNCT':True},
{'LOWER': 'especially'},
{'DEP':'nummod','OP':"?"},
{'DEP':'amod','OP':"?"},
{'POS':'NOUN'}]
matcher.add("matching_1", None, pattern)
matches = matcher(doc)
span = doc[matches[0][1]:matches[0][2]]
print(span.text)
|
2. 用于关系提取的子树匹配
基于规则的简单方法适用于信息提取任务。但是,它们有一些缺点和缺点。
我们必须非常有创造力才能提出新的规则来捕捉不同的模式。很难构建在不同句子中很好地概括的模式。
为了增强基于规则的关系/信息提取方法,我们应该尝试理解手头句子的依赖结构。
让我们取一个示例文本并构建其依赖关系图树:
| text = "Tableau was recently acquired by Salesforce."
# Plot the dependency graph
doc = nlp(text)
displacy.render(doc, style='dep',jupyter=True)
|
输出:
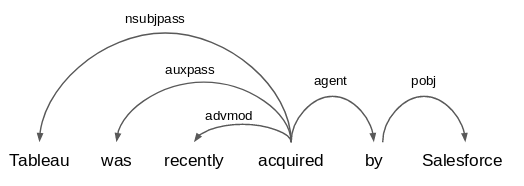
你能在这句话中找到任何有趣的关系吗?
如果您查看句子中的实体 - Tableau和Salesforce - 它们与术语“收购”相关。因此,我可以从这句话中提取的模式是“Salesforce收购了Tableau”或“X收购了Y”( “Salesforce acquired Tableau” or “X acquired Y”)。
现在考虑一下这句话:"Careem, a ride-hailing major in the middle east, was acquired by Uber."。
它的依赖关系图将如下所示:
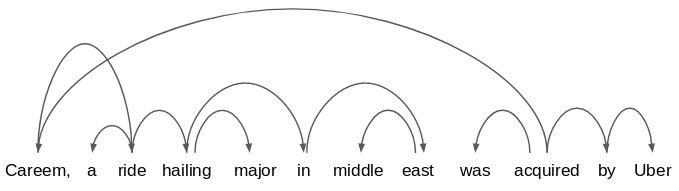
很可怕,对吧?
不用担心! 我们所要检查的是,在多个句子之间,哪些依赖关系路径是通用的。此方法称为子树匹配。
例如,如果我们将此语句与前一个语句进行比较:
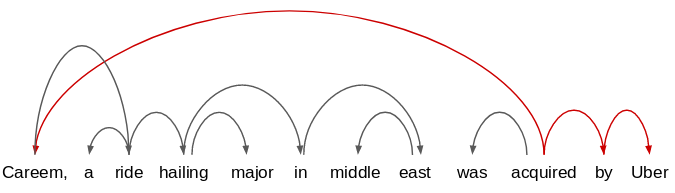
 我们将只考虑常见的依赖路径,并提取实体以及它们之间的关系(获取)。因此,从这些句子中提取的关系是:
我们将只考虑常见的依赖路径,并提取实体以及它们之间的关系(获取)。因此,从这些句子中提取的关系是:
- Salesforce acquired Tableau
- Uber acquired Careem
让我们尝试在Python中实现这种技术。我们将再次使用spaCy,因为它可以很容易地遍历依赖关系树。
我们将首先看一下句子中单词的依赖标签和POS标签:
| text = "Tableau was recently acquired by Salesforce."
doc = nlp(text)
for tok in doc:
print(tok.text,"-->",tok.dep_,"-->",tok.pos_)
|
输出:
| Tableau --> nsubjpass --> PROPN
was --> auxpass --> VERB
recently --> advmod --> ADV
acquired --> ROOT --> VERB
by --> agent --> ADP
Salesforce --> pobj --> PROPN
. --> punct --> PUNCT
|
在这里,“Tableau”的依赖关系标签是nsubjpass,它代表一个被动的主题(因为它是一个被动的句子)。另一个实体“Salesforce”是这个句子中的对象,术语“获得”是句子的根,这意味着它以某种方式将对象和主语联系起来。
让我们定义一个函数来执行子树匹配:
| def subtree_matcher(doc):
x = ''
y = ''
# iterate through all the tokens in the input sentence
for i,tok in enumerate(doc):
# extract subject
if tok.dep_.find("subjpass") == True:
y = tok.text
# extract object
if tok.dep_.endswith("obj") == True:
x = tok.text
return x,y
|
在这种情况下,我们只需要找到所有这些句子:
- 具有两个实体,并且
- 术语“获得”(acquired)作为句子中唯一的根(ROOT)
然后,我们可以从句子中捕获主语和宾语。我们调用上面的函数subtree_matcher(doc)
输出: (“Salesforce”、“Tableau”)
在这里, 主体是收购者 , 客体是被收购的实体 。让我们使用相同的函数 subtree_matcher()来提取由相同关系(“acquired”)相关的实体:
| text_2 = "Careem, a ride hailing major in middle east, was acquired by Uber."
doc_2 = nlp(text_2)
subtree_matcher(doc_2)
|
输出: (“Uber”、“Careem”)
你看到这里发生了什么吗?这句话有更多的单词和标点符号,但是,我们的逻辑仍然有效并成功地提取了相关实体。
但是等等 - 如果我将句子从被动语态更改为主动语态怎么办?我们的逻辑还能行得通吗?
| text_3 = "Salesforce recently acquired Tableau."
doc_3 = nlp(text_3)
subtree_matcher(doc_3)
|
输出: (“Tableau”、“”)
这并不是我们所期望的。该函数无法捕获“Salesforce”,并错误地将“Tableau”作为收购方返回。
那么,什么地方会出错呢?让我们理解这句话的依赖关系树:
| for tok in doc_3:
print(tok.text, "-->",tok.dep_, "-->",tok.pos_)
|
输出:
| Salesforce --> nsubj --> PROPN
recently --> advmod --> ADV
acquired --> ROOT --> VERB
Tableau --> dobj --> PROPN
. --> punct --> PUNCT
|
事实证明,术语“Salesforce”和“Tableau”的语法功能(主语和宾语)在主动语态中已经互换。但是,现在主题的依赖项标记已从“nsubjpass”更改为“nsubj”。 此标记表示句子位于活动语态中。
我们可以使用此属性来修改子树匹配函数。下面给出的是子树匹配的新函数:
| def subtree_matcher(doc):
subjpass = 0
for i,tok in enumerate(doc):
# find dependency tag that contains the text "subjpass"
if tok.dep_.find("subjpass") == True:
subjpass = 1
x = ''
y = ''
# if subjpass == 1 then sentence is passive
if subjpass == 1:
for i,tok in enumerate(doc):
if tok.dep_.find("subjpass") == True:
y = tok.text
if tok.dep_.endswith("obj") == True:
x = tok.text
# if subjpass == 0 then sentence is not passive
else:
for i,tok in enumerate(doc):
if tok.dep_.endswith("subj") == True:
x = tok.text
if tok.dep_.endswith("obj") == True:
y = tok.text
return x,y
|
让我们在主动语态句子上尝试这个新功能new_subtree_matcher(doc_3)
输出: (“Salesforce”、“Tableau”)
输出正确。让我们将前面的被动句子传递给此函数:
| new_subtree_matcher(nlp("Tableau was recently acquired by Salesforce."))
|
输出: (“Salesforce”、“Tableau”)
这正是我们一直在寻找的。我们使该函数稍微通用一些。我敦促您深入研究不同类型句子的语法结构,并尝试使此功能更加灵活。
尾注
在本文中,我们学习了信息提取,关系和三元组的概念,以及关系提取的不同方法。就个人而言,我真的很喜欢做关于这个主题的研究,并计划再写几篇关于更高级的信息提取方法的文章。
虽然我们已经覆盖了很多领域,但我们刚刚触及了信息提取领域的表面。下一步是在实际文本数据集上使用本文中学到的技术,并查看这些方法的有效性。
请随时查看以下有关从维基百科文本中提取关系和三元组的文章,并构建知识图谱。
如果你是NLP世界的新手,我强烈建议你参加我们关于这个主题的热门课程:
spaCy V3.0 基于规则匹配----高效的短语匹配器和依存句法匹配器
1 短语匹配器(PhraseMatcher)
1.1 基本用法
对于需要匹配大型术语列表的情况,可以通过PhraseMatcher和创建Doc对象来代替词符匹配模式(token patterns),可以获得总体上 更高的效率 。Doc模式可以包含单个或多个词符。
| import spacy
from spacy.matcher import PhraseMatcher
nlp = spacy.load("zh_core_web_sm")
matcher = PhraseMatcher(nlp.vocab)
terms = ['失速区','喘振区','油膜破坏','电机漏磁']
# 注意:只有使用 nlp.make_doc 才能加速
patterns = [nlp.make_doc(text) for text in terms]
matcher.add("TerminologyList", patterns)
doc = nlp("轴承绝缘击穿,电机漏磁电流通过轴承造成油膜破坏。二次风系统挡板误关,引起系统阻力增大,造成风压与进入的风量不匹配,使风机进入喘振区。")
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
|
注意:patterns 是一个Doc列表。
创建patterns,每个短语都必须使用nlp对象进行处理。如果加载了预训练模型,则在循环或列表中执行此操作很容易变得低效和费时。如果您只需要分词和词法属性,那么可以运行nlp.make_doc,它只使用了分词器(tokenizer)。当然还可以使用nlp.tokenizer.pipe方法,将文本作为流进行处理,以得到进一步的速度提升。
错误用法:
* patterns = [nlp(term) for term in LOTS_OF_TERMS]
正确用法:
patterns = [nlp.make_doc(term) for term in LOTS_OF_TERMS]patterns = list(nlp.tokenizer.pipe(LOTS_OF_TERMS))
1.2 匹配其他Token属性
默认情况下,PhraseMatcher将逐字匹配Token的文本,Token.text. 但通过在初始化时设置attr参数,可以更改匹配器(PhraseMatcher)在将短语模式(patterns)与文档进行比较时使用的Token属性。
注意:在前面的例子中,生成patterns列表用的是nlp.make_doc,它只使用了分词器(tokenizer)。对于本节需要匹配其他Token属性的情况,就要根据需要加入相应的组件。你可以直接使用nlp或通过 nlp.select_pipes()选择性的禁用某些组件。
比如:根据形状匹配数字Token(如IP地址)。使用Token的Shape属性将不必担心这些字符串如何分词,并且能够根据几个示例找到Tokens及其组合。下面我们将匹配形状ddd.d.d.d和ddd.ddd.d.d:
| matcher = PhraseMatcher(nlp.vocab, attr="SHAPE")
matcher.add("IP", [nlp("127.0.0.1"), nlp("127.127.0.0")])
doc = nlp("通常路由器有像'192.168.1.1'或'192.168.2.1'这样的IP地址。")
for match_id, start, end in matcher(doc):
print("Matched based on token shape:", doc[start:end])
|
当然从理论上讲,此方法对POS等属性也同样适用。例如,基于词性标签(tag)匹配的模式nlp(“我喜欢花”)将返回“我爱狗”的匹配。还可以匹配像IS_PUNCT这样的布尔属性,以匹配具有与模式相同的标点符号和非标点符号序列的短语。但是这么做很容易让人迷惑,且与编写一个或两个Token模式相比也没有太大的优势。
2 依存句法匹配器
DependencyMatcher使用Semgrex操作符匹配依存句法分析中的模式。它需要一个包含依存句法解析器的模型,比如DependencParser。DependencMatcher模式没有定义Matcher patterns中相邻Token的列表,而是匹配依存关系分析中的Roken并指定它们之间的关系。
依存句法匹配器的patterns由字典列表组成,每个字典描述要匹配的Token及其与patterns中现有Token的关系。除了第一个字典(它仅使用RIGHT_ID和RIGHT_ATTRS定义anchor token)之外,每个pattern 都应该具有以下4个键:
|
键名
|
说明
|
|
LEFT_ID
|
关系符左边的节点名称,该节点此前要出现在patters字典列表
str
|
|
REL_OP
|
表明左右两节点关系的操作符
str
|
|
RIGHT_ID
|
关系符右侧节点名称(该名称不能重复)
str
|
|
RIGHT_ATTRS
|
要匹配的关系符右侧节点的属性,其格式与Token Matcher中的patters相同
Dict[str, Any]
|
添加到patterns中的每个附加Token,都通过关系操作符REL_OP链接到现有名称为LEFT_ID的Token。新Token被命名为RIGHT_ID并由具有RIGHT_ATTRS描述的属性。
重要提示:由于用LEFT_ID和RIGHT_ID来作为识别Token的唯一名称,patters字典列表中的顺序就非常重要。所有作为LEFT_ID出现的节点,必须在前面的字典中作为RIGHT_ID被定义过!!!!
依存句法匹配器可用的操作符
|
符号
|
说明
|
|
A < B
|
A是B的直接子节点
|
|
A > B
|
A是B的直接头节点
|
|
A << B
|
A能够通过多个子节点到头节点关系跳转路径到达B
|
|
A >> B
|
A能够通过多个头节点到子节点关系跳转路径到达B
|
|
A . B
|
A是B的位置左邻节点, 即:A.i == B.i - 1 (A、B在同一依存解析树中,i是其Doc中的位置索引。 下同)
|
|
A .* B
|
A是B的位置前序节点, 即:A.i < B.i
|
|
A ; B
|
A是B的位置右邻节点, 即:A.i == B.i + 1
|
|
A ;* B
|
A是B的位置后序节点, 即:A.i > B.i
|
|
A $+ B
|
B是A的右邻同级节点, 即:A.head == B.head and A.i == B.i - 1
|
|
A $- B
|
B是A的左邻同级节点, 即:A.head == B.head and A.i == B.i + 1
|
|
A $++ B
|
B是A的位置后序同级节点, 即:A.head == B.head and A.i < B.i
|
|
A $-- B
|
B是A的位置前序同级节点, 即:A.head == B.head and A.i > B.i
|
如果要从以下句子中找出“造成”什么后果:
1 “轴承绝缘击穿,电机漏磁电流通过轴承造成油膜破坏。”
2 “冷渣器内部冷却水管泄漏造成灰渣板结。”
我们要找到以下关系:
- 造成的直接宾语(dobj)
- 直接宾语(dobj)的复合名词修饰或形容词修饰(也可以没有修饰)
| nlp = spacy.load("zh_core_web_sm")
matcher = DependencyMatcher(nlp.vocab)
pattern = [
{
"RIGHT_ID": "anchor_word",
"RIGHT_ATTRS": {"ORTH": "造成"}
},
{
"LEFT_ID": "anchor_word",
"REL_OP": ">",
"RIGHT_ID": "w_object",
"RIGHT_ATTRS": {"DEP": "dobj"}
},
{
"LEFT_ID": "w_object",
"REL_OP": ">",
"RIGHT_ID": "object_modifier",
"RIGHT_ATTRS": {"DEP": {"IN":["compound:nn","amod"], "OP":"?"}}
}
]
matcher.add("FOUNDED", [pattern])
doc = nlp("冷渣器内部冷却水管泄漏造成灰渣板结。轴承绝缘击穿,电机漏磁电流通过轴承造成油膜破坏。")
matches = matcher(doc)
print(matches)
for match_id, token_ids in matches:
for i in range(len(token_ids)):
print(pattern[i]["RIGHT_ID"] + ":", doc[token_ids[i]].text)
|
运行结果:
| [(4851363122962674176, [5, 7, 6]), (4851363122962674176, [19, 21, 20])]
anchor_word: 造成
w_object: 板结
object_modifier: 灰渣
anchor_word: 造成
w_object: 破坏
object_modifier: 油膜
|
提高匹配速度的重要提示:
当token patterns能够潜在匹配句子中的许多token,或者当关系运算符在依存关系解析中的路径较长时(如<<、>>、以及;关系运算符),匹配速度可能会比较慢。
为了提高匹配速度,操作符尽可能具体。例如,尽量使用 > 而不是 >> ,使用包含语义标签和其他Token属性,而不是像 {} 匹配句子中任何Token。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: Prateek Joshi , Cxrlyy
来源: https://www.analyticsvidhya.com/blog/2019/09/introduction-information-extraction-python-spacy/ , https://blog.csdn.net/u014607067/article/details/114371755