使用 Google Trend、Python 和 Ahrefs 查找关键字商机¶
长期以来,Google Trend一直是 SEO 的一个强大工具。了解历史、当前和预测未来趋势,让我们了解季节性和代际事件(如冠状病毒)等。2019 年谁会想到卫生纸在 2020 年 3 月在潮流中达到 100?谷歌趋势的网页界面是超级用户友好,你可以找出很多,但它只提供与您的网站脱离的数据。如果您可以引入一些排名数据来查找趋势关键字的网址排名,那该数据会如何。这些将是您可以关注现在或预测未来的机会。
要求和假设¶
下载 Ahrefs 关键字数据¶
- 登录 ahrefs.com
- 单击左侧栏上的"有机关键字"
- 单击数据表右上右侧的"导出"
- 选择"完整报告"和 UTF-8 格式
- 将下载的 csv 重命名为排名.csv
启动脚本¶
我的建议是开发这个脚本在谷歌Colab,因为我们使用一个特定的Colab库和扩展。
首先,让我们安装模块 pytrends 这将有助于我们利用谷歌趋势数据。如果您使用的是Colab,请先在pp3之前放一个感叹号,所以!pip3。
pip3 install pytrends
接下来,我们导入所需的模块。 Pytrends 与 Google Trend进行沟通。来自Pytrends的数据是 JSON, Pandas 一部分, 所以我们需要 熊猫来处理。 脚本 延迟的时间,以减少与谷歌趋势的摩擦。 data_table Google 扩展的一部分,您将很快加载,以帮助增强数据框视觉对象。显然,如果您不在 Google Colab 中运行此功能,您可以省略该模块和扩展。
如果您在 Google Colab 中运行此内容,您需要使用其数据表扩展名,该扩展将 Pandas 数据帧视觉对象增强为电子表格中。
分配关键字并加载 Arefs 数据¶
接下来,我们创建一个变量来存储我们的关键字。这是我们将搜索谷歌趋势。
现在,让我们将 Ahrefs 关键字数据加载到名为 rankdf 的熊猫 数据帧中 。如果您使用的是 Google Colab,不要忘记从左侧栏文件上传区域上传此文件。一旦 csv 在数据帧中,我们希望删除(删除)除关键字和 URL 列的所有 内容。我们的 排名 将只包括这两列。
配置 pytrend 模块¶
是时候使用 pytrends 模块了 。首先,我们调用 TredReq() 函数,并加载 到 pytrends 变量 中作为对象。然后,我们 kw_list 调用有效负载函数用于搜索数据。此变量必须是一个列表,即使在此脚本中,我们将使其成为单个列表项。其他人可能会随意将其扩展到多个关键字中。然后,我们构建发送到 Google 趋势的请求。
访问我们关键字的相关主题¶
现在我们可以访问不同类型的数据。 完整的文件在这里。出于此脚本的目的,我们将访问 "相关主题 " 和 "相关查询 " 的数据 。首先,我们将访问 [ 相关查询 ]。我们想要的子数据是" 格式化值 ", 这是"topic_title", 这是相关关键字爆发 的名称,然后"topic_type", 它给出了关键字(实体)一个类别。
要访问所有这些内容,我们需要深入了解 gettopics 对象中包含的数据 ,并将其全部转换为列表。
最后,我们要在 Try/例外中包装数据分配, 因为如果您向 Google Trends 发送一个单词,其中它不返回数据,因为可能该词是假的或不得人心的,因此它会返回错误。我们将分配一个变量来标记如果没有数据,请稍后使用。
我们使用 的模块 pytrend 是一个非官方的 API。这意味着没有关于如何与 Google 趋势沟通的官方指南。如果滥用它可能导致谷歌阻止你。我得到 "退出" 响应并不罕见, 这意味着我需要等待几秒钟, 然后重试。为了帮助我们避免滥用 API,我们使用时间模块在脚本延迟中添加。
访问我们关键字的相关查询¶
我们已经有我们的 [相关主题 ] 数据, 它现在的时间得到 [ 相关查询] 数据.这个过程类似于我们已经为 [相关主题 ] 所做的 。我们要获取的数据是 [ 热门查询] 和 [ 上升查询 ]。我们抓住这两个,但正如您稍后将看到的,对于与您加载的 CSV 匹配的关键字,您只能使用其中一个来匹配和显示在最终数据帧中。
在这一点上,我们有我们所有的数据,现在我们只需要把它形成最终的数据框架,我们查看。开始我们检查变量停止是否等于1,如果它这样做,打印一条消息告诉我们,无论我们使用什么关键字,没有足够的数据谷歌发送给我们,所以有一个错误。接下来,我们需要将所有数据捆绑到变量"数据 "中 。目前,它们都在单独的列表变量中。你会注意到我省略了 [ 上升]。 这是这个脚本的要点,你需要选择[ 顶部]或 [ 上升 ]使用,当然,你可以来回切换。这是因为,无可否认,我不确定如何合并数据框,其中 ahrefs 数据的关键字列与数据帧中的两列(顶部和上升)匹配。让我知道, 如果你知道!
合并列表和创建主数据帧¶
最后,我们从我们创建的称为数据的主列表中创建一个数据框,并命名列。
合并谷歌趋势和 Ahrefs 数据框架在一起¶
在这一点上,我们有我们的数据框架与谷歌趋势数据。我们现在要做的是将此数据框合并到我们使用此脚本开头的 Ahrefs CSV 创建的数据帧中,该数据框基于 Google 趋势数据 帧中的" 热门查询"(或"上升")列中的 Ahrefs 关键字列数据匹配数据。我们将使用 fillna() 函数 将任何 NaN 值(无数据)替换为明显的双炒作。
在合并过程中,添加了 Ahrefs" 关键字 "列, 但这是"热门 查询"(或"上升",如果选择了)列的重复项,因此让我们将其从数据帧中删除。
我们现在在最后一步!
剩下的就是打印出关键字,以防忘记,然后打印出最终的数据框。为此,我们将利用我们在开头添加的扩展。我们感受到了 数据表()的最终 数据框架和宾果!随意调整每页值的行数(Google 通常返回 15-20 行),如果您想要在左侧添加编号的行include_index True 。如果您未使用 Google Colab 或未使用 data_table,请 转到下面的替代代码。
最后一步替代方案¶
调整 head() 中的数字,以显示要显示的行数。
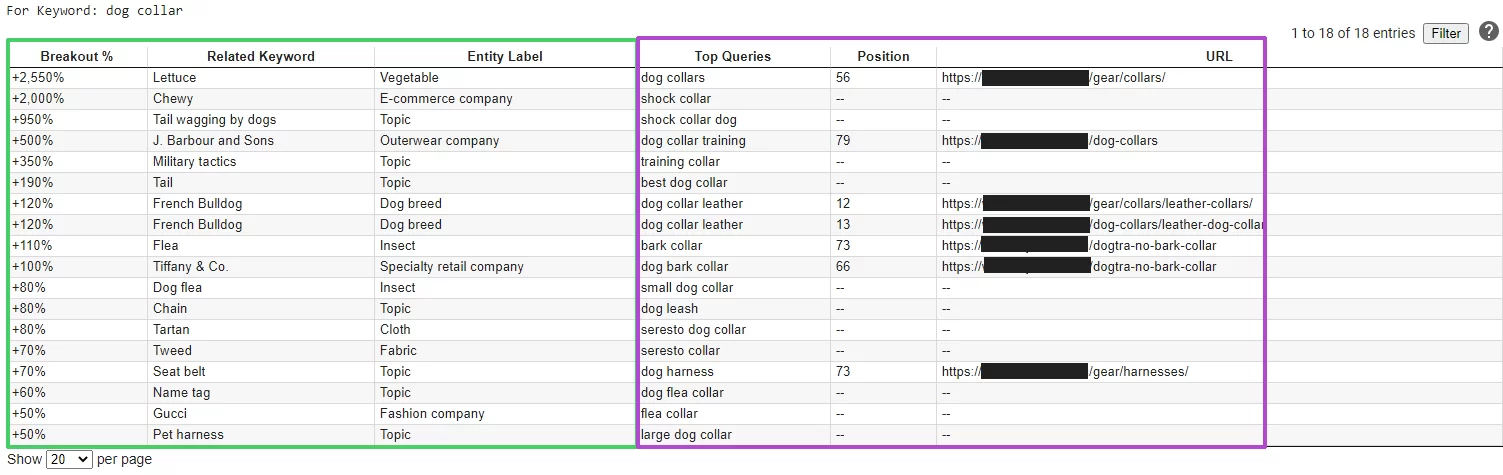
下面是预期输出的示例。在此示例中,我使用了宠物店的 Ahrefs 数据和关键字"狗领"。请注意,彩色部分是相互相关的列,它们除了使用相同的关键字从 Google 趋势生成以外的其他交叉关联。
结论¶
谷歌趋势一直是访问历史趋势和预测新趋势的有力工具。能够从 API 的角度利用他们的数据,这为巨大的可能性打开了大门。本教程提供了一小片可供您访问的数据和一个奇异的应用程序。您可以轻松地将其扩展到接受多个关键字、将数据存储在数据库中、混合来自其他源的数据或访问其他数据区域。
[查看全部](https://importsem.com/author/dethfire/)
作者 Greg Bernhardt 的最新帖子
-
使用 Python 创建自定义推特推文警报系统 2020年12月8日
-
使用 Python 查找关键字类别的搜索卷上限 2020年11月2日
-
分析爬网的 PDF 文本使用 Python 的 SEO 2020年10月21日
原文翻译自网文,作者: Greg Bernhardt
原文: https://importsem.com/find-keyword-opportunities-with-google-trends-python-and-ahrefs/#abh_posts