GPT + Stable Diffusion 生图工作流
简介
在上一篇文章中,我大致介绍了stable diffusion(以下简称sd)的api接口调用方法,很多人对实践的工作流感兴趣,这里,就将我实现的一个简单工作流:在gpt的动态提示词介入以及提前设置好的静态sd模板下的一个简单工作流系统,做大致介绍
结论先行,这是我们最后可以生成的结果
只需要简单的参数,就可以生成不错的效果(当然,这篇内容不会包括下图中的ui开发)

sd工具简介
基于上一篇文章的知识,相信大家对api调用已经有所了解,基于此,我写了个简易的sd参数模板生成工具,这是仓库链接:
Stable Diffusion Tool
这个工程能做到的事情如下:
1. 具有gradio做的简易ui页面,支持sd的参数导入、图生图和文生图的基本参数填写(但目前因为我有私人项目正在跟进,还没有时间去优化整个ui界面,只能保证能够正常使用,如果真的有对这个工具感兴趣的,下次再来详细介绍如何使用)
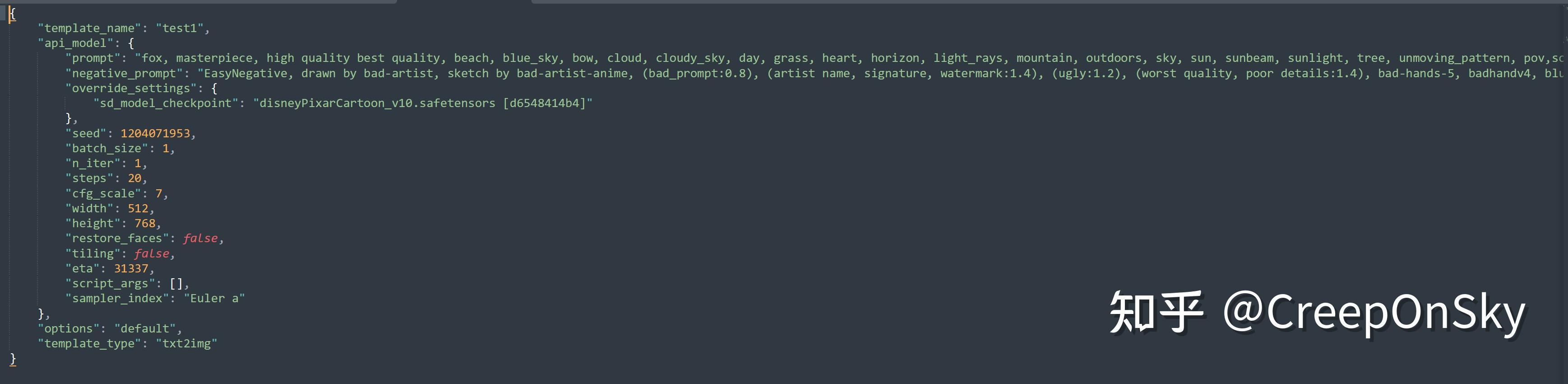
2. 支持保存成json文件模板,用来方便后续调用以及参数修改,以下是一个简易的已经生成好的参数模型,这样用户之间可以直接复制分享或者直接修改其中的参数,来进行动态调整
3. 该项目具有直接请求sd的方法接口,具体代码在apiutil文件中的submitall,如果只对提交感兴趣可以研究一下这块代码
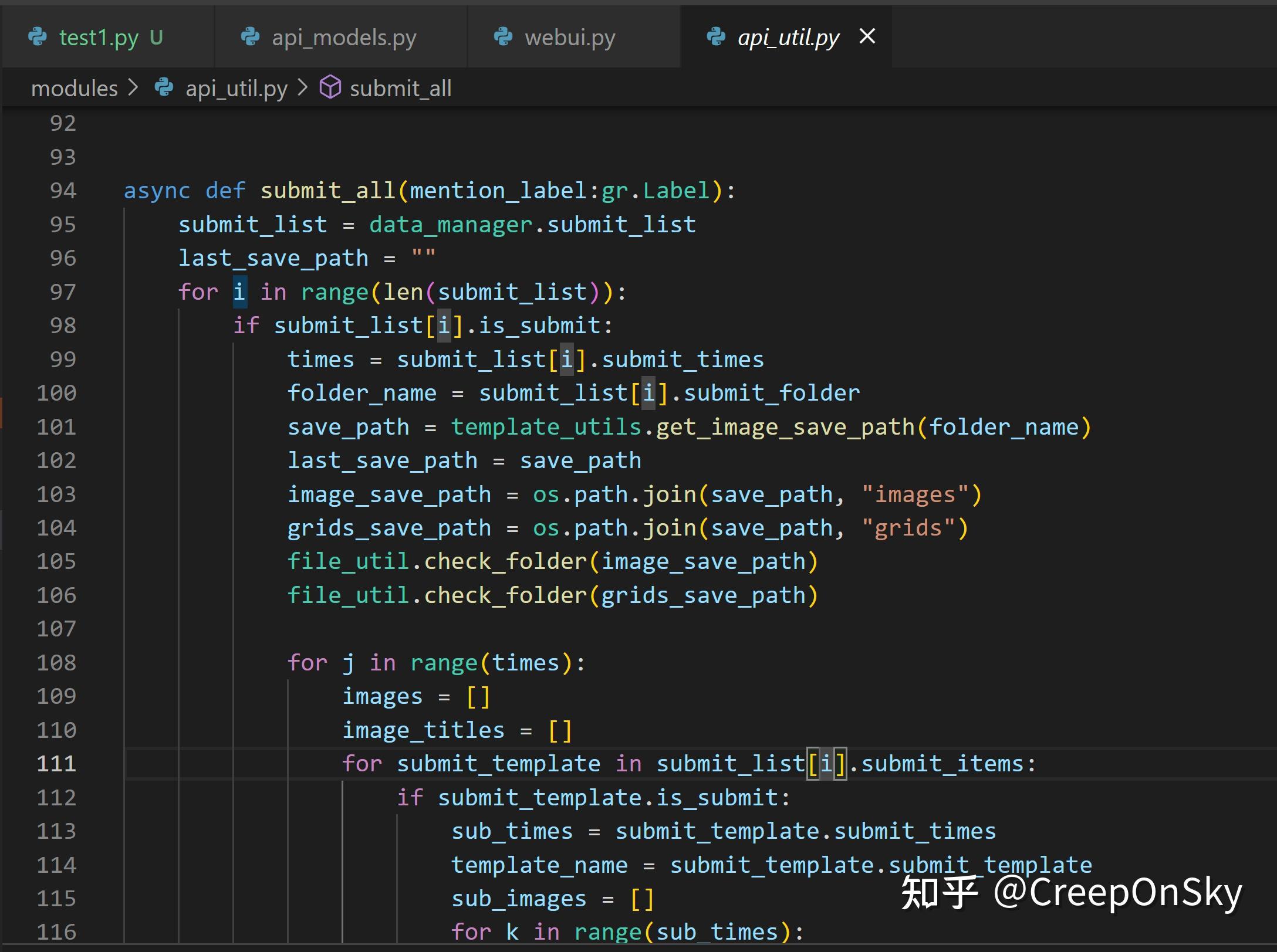
4. 该项目可以批量提交不同模板。我的模板设计思路如下
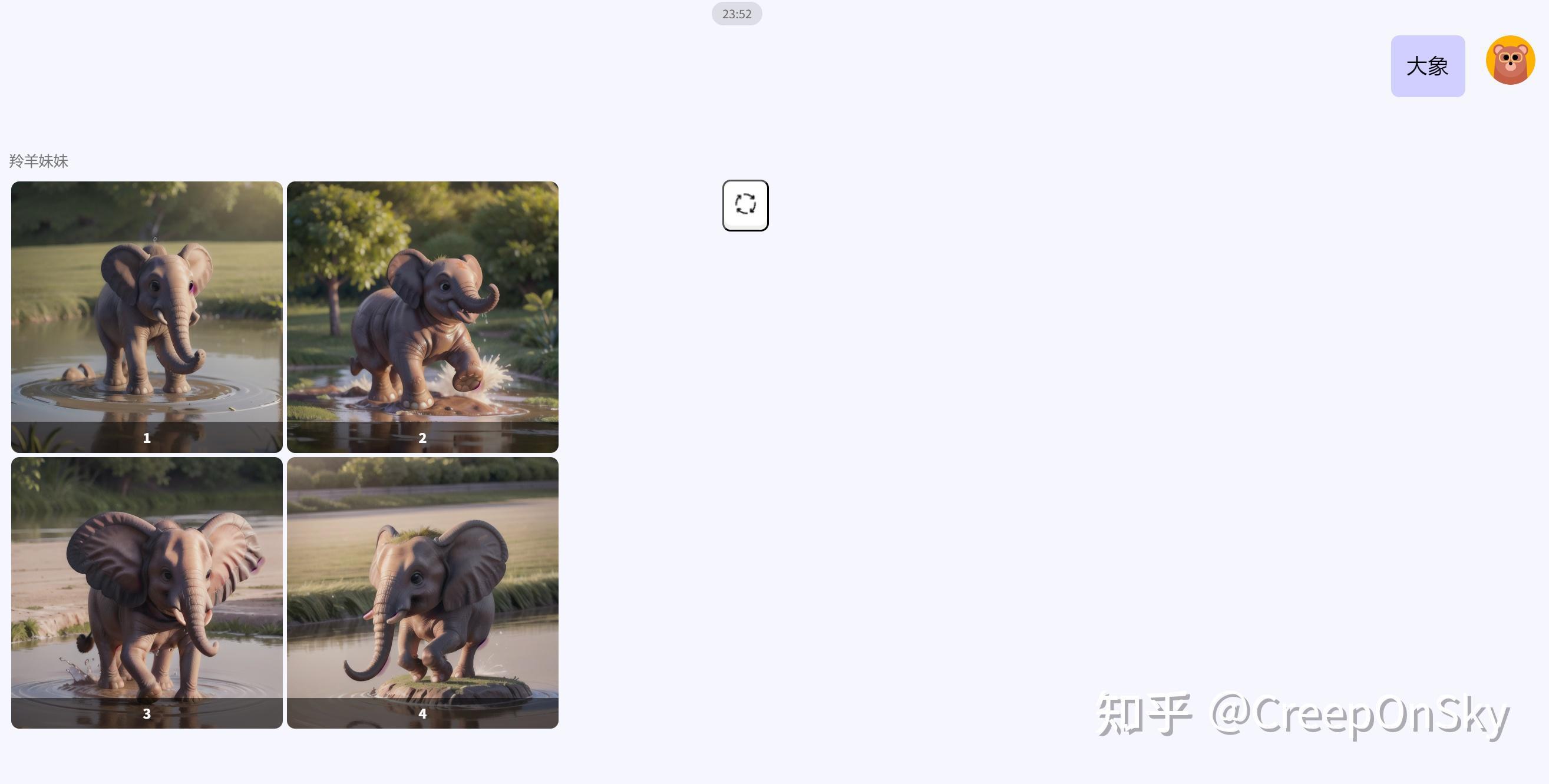
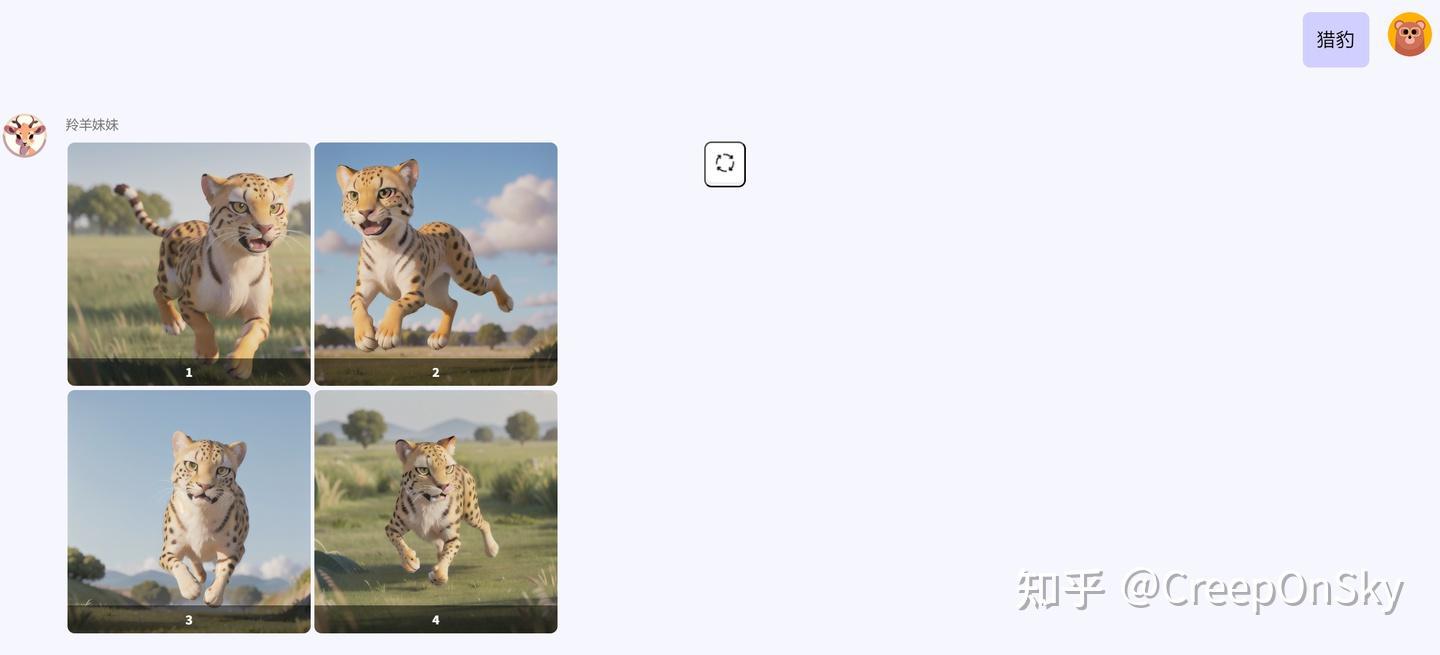
在这样的设计思路下,我们可以一次性提交模板文件夹1中的所有模板文件,并且自动将每次生成图片的放入一个grid图片进行对比,这功能类似于sd的x/y参数,但是脱离了sdwebui,而是采用api方式提交,我们对每个模板的参数可控性也更高,以下是做了三个模板,分别借助了三个动物原图进行图生图的不同模板设定,生成效果如下

gpt的api调用
有了sd工具的加成,我们可以实现sd的快速模板实现,但只是静态的参数实现,我们需要加入一些动态的参数
但是,我们将繁琐的参数设定交给用户并不是一个很好的决定,目前大部分国内的通用生图平台都是让用户去选择很多参数来进行生图
我个人想法更倾向于我们内部固定模板,用户选择一个方向,将提示词的具体参数交给gpt来做,在这个的前提,需要咱们去学会gpt的api基础调用,这里用python,做一下简单实现,如果已经学会的朋友当然可以跳过这步骤
这是gpt的官方文档,感兴趣的可以自行查看文档了解
文档 Create chat completion
我们有几个方式实现gpt的api调用,但本质都是一样的,进行网络请求
这里我采取官方提供的openai库,来进行调用,首先安装openai,
然后这是我从项目中抽离的关键代码
| from flask import Flask, request
from flask_socketio import SocketIO
from openai import ChatCompletion
import openai
app = Flask(__name__)
socketio = SocketIO(app, cors_allowed_origins='*')
@socketio.on('connect')
def handle_connect():
print('Client connected')
sid = request.sid
@socketio.on('gpt_chat')
def connect(data):
sid = request.sid
key = data['key']
messages = data['messages']
model = data['model']
client_sid = data['client_sid']
openai.api_key = key
full_message = ""
completion = ChatCompletion.create(model=model, messages=messages,temperature=0, stream=True)
for line in completion:
chunk = line['choices'][0].get('delta', {}).get('content', '')
full_message += chunk
if chunk:
socketio.emit('message', {
'message': chunk,
'client_sid': client_sid,
}, room=sid)
socketio.emit('gpt_chat', {
'full_message': full_message,
'client_sid': client_sid,
}, room=sid)
return {"status": "connected", "full_message": full_message, "client_sid": client_sid}
if __name__ == '__main__':
socketio.run(app,port=5001,host='0.0.0.0', debug=True)
|
这里的ChatCompletion是openai官方提供的方法,可以创建一个基本的对话实例然后我们需要将我们的选用模型和key,以及消息传入给他
key当然就是我们的申请到的openai 的key
model从下面选择你想用的模型,但其实我们常用的也就gpt-4和gpt-3.5-turbo,32k的会比较贵在sd的项目中必要性并不大
| gpt_model_list = ['gpt-4', 'gpt-4-0314', 'gpt-4-32k', 'gpt-4-32k-0314', 'gpt-3.5-turbo', 'gpt-3.5-turbo-0301']
|
最重要的是我们的message的设置
在openai的message设置中,message的构成由role和content组成,role分别代表着gpt回答,我们提前设定好的system prompt, 以及用户的询问
role:The role of the author of this message. One ofsystem,user, orassistant.
这是一个简单的messages构成
这里设置了简单的一个system词,你可以理解为告诉gpt你的角色,然后进行了一次“你好”的提问,gpt进行回复,然后我们再次进行提问,再次回复,这就意味着我们其实每次都要告诉gpt前面的历史内容,这也是gpt具有记忆的原因
| "messages": [
{
"role": "system",
"content": "Your identity is now Mr. Lion, your role is to act as a friendly and engaging teacher for young children. "
},
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好!我是语言模型AI,有什么我能为您效劳的吗?"
},
{
"role": "user",
"content": "我想问一下你是谁"
},
{
"role": "assistant",
"content": "我是一个自然语言处理模型AI,开发者使用自然语言编程技术来打造我的语言模型。我可以帮助您处理自然语言相关的任务和问题,比如聊天、翻译、语音识别、文本生成等。"
}
]
|
还剩余一个点,是这里用到的stream,这是用来实时回复,gpt有两个回复方式,一个是一次性回复所有消息,一个是流传输,一次性回复一点,但是会更加快速,你使用的gpt官方网址,所用到的就是流传输机制,一次性回复一点不必等待,这也是我推荐的方式
这里用到了python的flask_socketio ,用来和客户端进行实时通信然后再所有消息发送完毕后,再将fullmessage一次性发送给客户端作为完结,剩余就不再赘述,openapi的调用非常简单
gpt+sd
有了以上的基础知识,我们先来在静态参数一些表示质量的以及风格的以及我们想要固定的大方向,制作成模板进行封装
这里以我已经制作好的一个模板文件为例,这里我们放入了一些简易的提示词作为基准,模型就用我们提前设定好的一个叫做
disneyPixarCartoon_v10.safetensors [d6548414b4]的模型
| {
"template_name": "1",
"api_model": {
"prompt": "In the middle of the screen, close shot,best quality, highres, masterpiece, cute",
"negative_prompt": "bad-picture-chill-75v easynegative ng_deepnegative_v1_75t, two heads, two mouths, human",
"seed": -1,
"batch_size": 4,
"n_iter": 1,
"steps": 20,
"cfg_scale": 7,
"width": 600,
"height": 600,
"eta": 1,
"sampler_index": "DPM++ SDE Karras"
},
"options": "default",
"template_type": "txt2img"
}
|
然后基于sdtools写了一个自定义的生成代码, 这里唯一需要关心的就是prompt参数,我们读取了folderName模板文件夹下的templateName模板参数信息,也就是上面的参数,然后将其转化为我们的model_data 实例
然后再将其中的prompt动态加入我们传入的prompt参数,即可实现gpt的动态参数部分,剩余的就是一下我自定义的生图之后的步骤了,比如替换传入的image,替换传入了controlnet的image
| @app.route('/submitbyprompt', methods=['POST'])
async def submit_by_prompt():
# 获取请求的文件和模板名称
prompt = request.form.get('prompt')
template_name = request.form.get('templateName')
folderName = request.form.get('folderName')
model_data = template_manager.get_info_in_template_path(folderName, template_name)
model_data.api_model.prompt = prompt + ", " + model_data.api_model.prompt
if model_data.template_type == ApiType.img2img.value:
image_file = request.files.get('image')
image_base64 = utils.imageFile_to_base64(image_file)
img2img:Img2ImgModel = model_data.api_model
img2img.init_images.clear()
img2img.init_images.append(image_base64)
img2img.mask=None
img2img.alwayson_scripts["ControlNet"]["args"]["image"] = image_base64
# 将文件保存到临时位置,或者处理文件以满足下一次请求的需求
images = await api_util.submit_once(model_data)
res = {'images': images}
# 将返回的结果发送给前端
return jsonify(res)
async def submit_once(data: TemplateBaseModel):
folder_name = "test"
save_path = template_utils.get_image_save_path(folder_name)
image_save_path = os.path.join(save_path, "images")
grids_save_path = os.path.join(save_path, "grids")
file_util.check_folder(image_save_path)
file_util.check_folder(grids_save_path)
images = []
image_titles = []
template_name = data.template_name
sub_images = []
if data.template_type == "txt2img":
save_image_name = f"{template_name}_txt"
txt2img_model = data.api_model
is_success, res = await txt2img_post_async(save_image_name, txt2img_model, image_save_path)
elif data.template_type == "img2img":
save_image_name = f"{template_name}_img"
img2img_model = data.api_model
is_success, res = await img2img_post_async(save_image_name, img2img_model, image_save_path)
if is_success:
sub_images = res
else:
return f"提交失败!报错如下:{res}"
save_image_name = f"{template_name}_sub_grid_"
if len(sub_images) > 1:
image = utils.merge_images_horizontally(sub_images, 3, os.path.join(grids_save_path, save_image_name))
elif len(sub_images) == 1:
image_data = base64.b64decode(sub_images[0])
image = Image.open(BytesIO(image_data))
return sub_images
|
这一步就已经实现了我们的动态参数放入,这一切都要基于我们能够有一个实例化的sd参数实例
之后,我们提前设定好gpt的system提示词放入message,这是我提前设定好的一个生成动物的system prompt作为参考
| As an AI text-to-image prompt generator of an animal theme,
your primary role is to generate detailed, dynamic, and stylized prompts for image
generation.
---
Example of tags:
Character/subject tags:
an adorable white and brown spotted kitten, (big bright eyes:1.2), sitting on a cozy armchair,
(pink nose:1.1), soft fur fluffed up
Background environment tags:
intricate garden, flowers, roses, trees, leaves, table, chair, teacup
Always Remember:
1. Prompt should follow (subject + background environment tag) format
2. Prompt should be within 10 words.
3. You might be given in Chinese, but always respond the prompt in English. English for '角
马' is wildebeest
4. ONLY use descriptive adjectives.
5. This is a prompt for kid's illustration, always give friendly prompt for the image
|
然后我们就是和gpt的对话过程了,我们将他的回复给到sd,进行生图
一些ui层面的代码我就不赘述,下面是我做的一个网页的效果,分别告诉gpt简单的参数,就可以得到很不错的效果,这应该是我们最终的目的


第一篇 GPT + Stable Diffusion 生图工作流
参考:
获取Midjourney API需要的Discord Token
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: CreepOnSky
来源: https://zhuanlan.zhihu.com/p/635462648