零基础读懂Stable Diffusion(III):怎么控制¶
由于原文篇幅较长,所以这里分为三篇文章进行讲解:
- 第一篇,主要讲“ 是什么 ”的问题,包括Stable Diffusion是什么,里面的各个模块是什么。
- 第二篇,主要讲“ 怎么办 ”的问题,也就是Diffusion怎么训练以及怎么使用的问题。
- 第三篇,也就是本篇,主要讲“ 如何控制 ”的问题,具体阐述语义信息到底是怎么影响生成图片的过程的。
接下来正式进入第三篇的介绍,谈谈语义信息到底是怎么影响生成图片的过程的。
上面一篇文章中我们着重讲述了如何训练Stable Diffusion中的unet,同时,也了解了在训练好unet之后怎么使用它来去除噪声以及生成图片。然而,还有一个重要的地方我们尚未提及,那就是 可控性 。我们如何用语言来控制最后生成的结果?答案也很简单—— 注意力机制 。在第一篇文章中我们讲到,一个unet除了要接收噪声图之外,还要接受我们用Text Encoder预先提取的 语义信息 。那这个语义信息怎么在生成图片的过程中使用呢?我们直接 使用注意力机制在unet内层层耦合 即可。下图中每个黄色的小方块都代表一次注意力机制的使用,而每次使用注意力机制,就发生了一次图片信息和语义信息的耦合。每一个unet内部,这样的操作都会发生很多次很多次,直到最后一个unet为止,一直不断重复这耦合的过程。
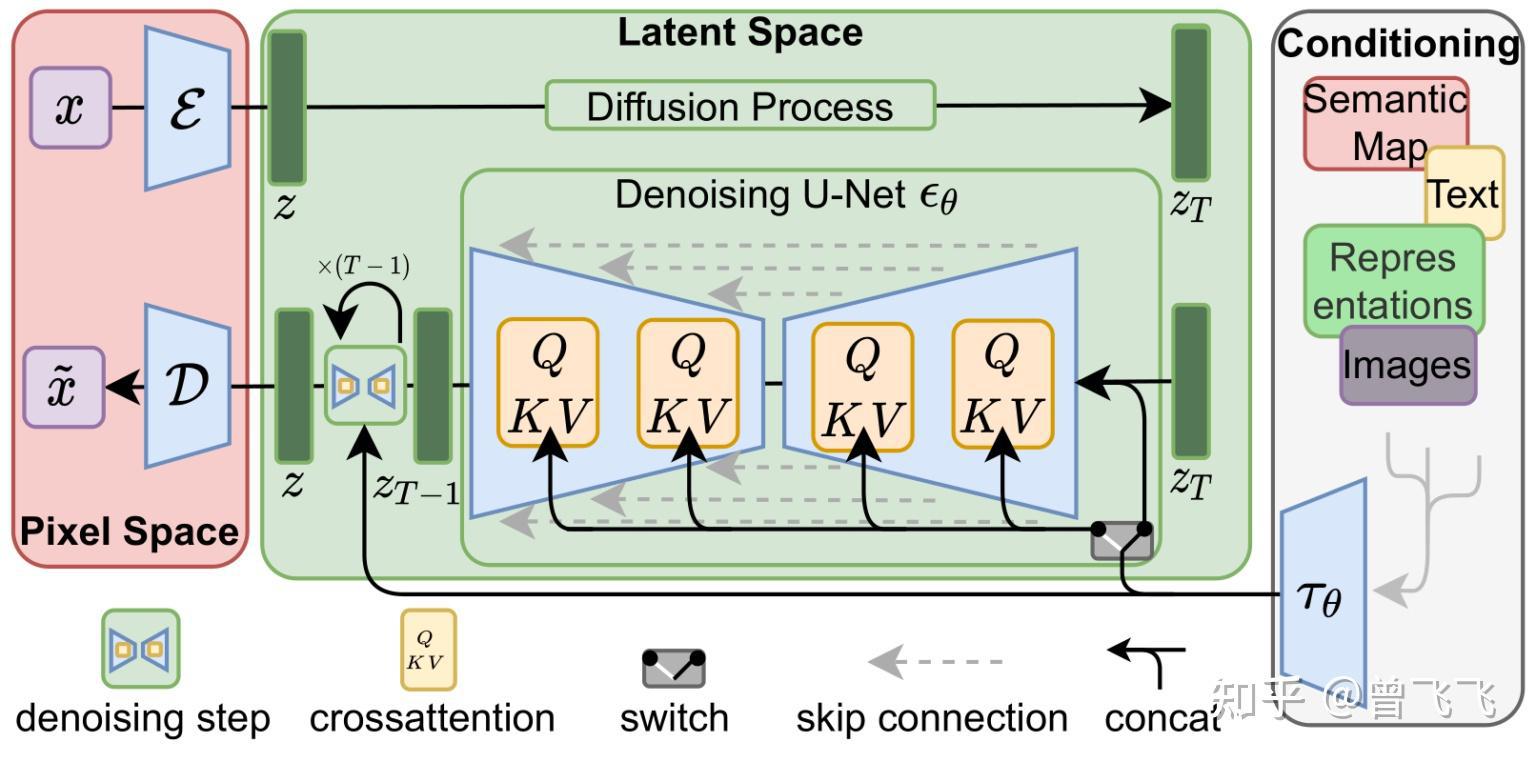
有人可能就要问了,语义信息是语义信息,图片信息是图片信息,怎么能用attention耦合到一块呢?计算机怎么把这两种完全不同的信息联系到一起的呢?这就要说到我们这篇文章的主角——CLIP模型了。
一,CLIP模型介绍¶
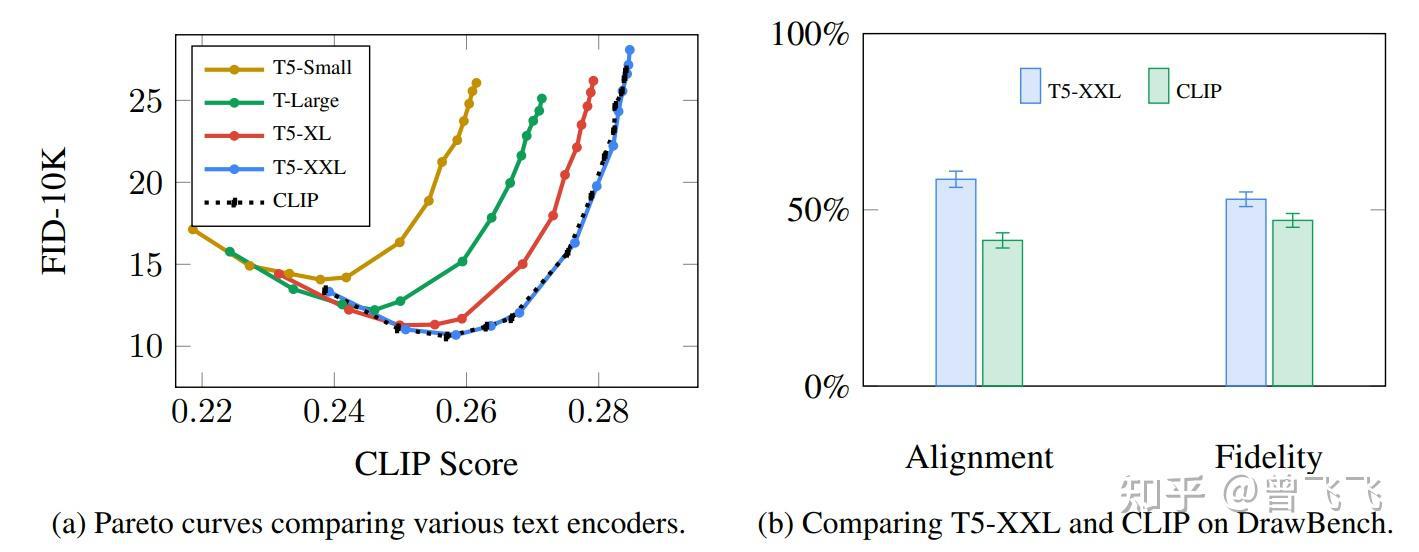
自从2018年Bert发布以来,Transformer的语言模型就成了主流。Stable Diffusion起初的版本便是用的基于GPT的CLIP模型,而最近的2.x版本换成了更新更好的OpenCLIP。语言模型的选择直接决定了语义信息的优良与否,而语义信息的好坏又会影响到最后图片的多样性和可控性。Google在Imagen论文中做过实验,可以发现不同语言模型对生成结果的影响是相当大的。
那像CLIP这样的语言模型究竟是怎么训练出来的呢?它们是怎么样做到结合人类语言和计算机视觉的呢?接下来我们就来好好了解一下。
首先,要训练一个结合人类语言和计算机视觉的模型,我们就必须有一个结合人类语言和计算机视觉的数据集。CLIP就是在像下面这样的数据集上训练的,只不过图片数据达到了可怕的4亿张而已。事实上,这些数据都是从网上爬取下来的,同时被爬取下来的还有它们的 标签 或者 注释 。

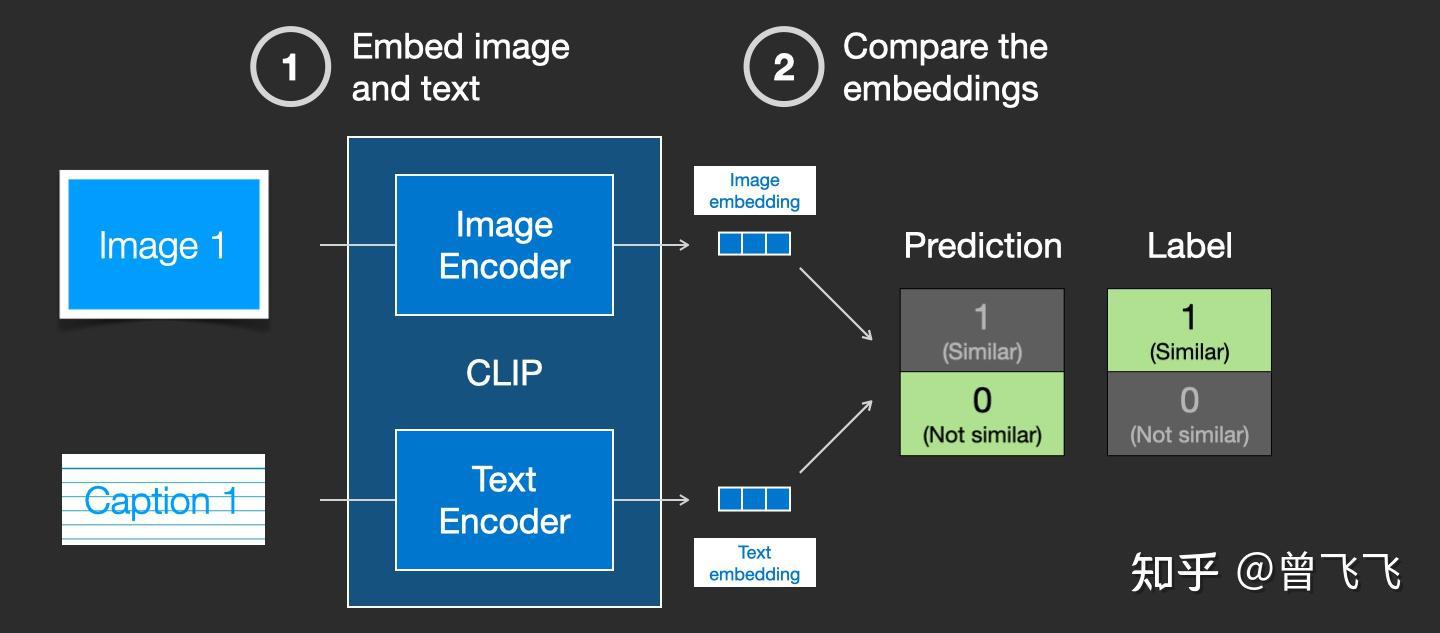
CLIP模型包含一个 图片Encoder 和一个 文字Encoder 。训练过程可以这么理解:我们先从训练集中随机取出一张图片和一段文字。注意,文字和图片 未必是匹配的 ,CLIP模型的任务就是 预测图文是否匹配 ,从而展开训练。在随机取出文字和图片后,我们再用图片Encoder和文字Encoder分别压缩成两个embedding向量,称之为图片embedding和文字embedding【下图两个蓝色3*1向量】。

然后我们用余弦相似度来比较两个embedding向量的 相似性 ,以判断我们随机抽取的文字和图片是否匹配。一开始的时候,就算图片和文字配对的很好,但由于我们的两个Encoder刚刚初始化,参数都是混乱的,因此两个embedding向量一定也是混乱的,计算出来的相似度往往会接近于0。这就会出现下图这种状况, 明明图文是一对,他们的label是similar,但是余弦相似度算出来的prediction却是not similar :
这个时候,标签(similar)和预测结果(not similar)不匹配,我们就根据这个结果去反向更新两个Encoder的参数:

不断地重复这个反向传播的过程,我们就能够训练好两个Encoder。对于配对的图片和文字,这两个Encoder最后就可以 输出相似的embedding向量 ,计算余弦相似度就可以得到接近1的结果。而对于不匹配的图片和文字,这两个Encoder就会输出很不一样的embedding向量,使得余弦相似度计算出来接近0. 这个时候,你给CLIP一张小狗的图片,同时再给出文字描述:“小狗照片”,CLIP模型就会生成两个相似的embedding向量,从而判断出文字和图片是匹配的。这个时候,计算机视觉和人类语言这两个原本不相干的信息就通过CLIP联系到了一块,二者就拥有了统一的数学表示了。你可以将文字通过一个Text Encoder转换成图片信息,也可以将文字通过Image Encoder转换成语言信息,二者就能够 相互作用 了。这也是Diffusion模型中可以通过文字生图片的秘密所在。
值得注意的是,就像经典的word2vec训练时一样,训练CLIP时不仅仅要选择匹配的图文来训练,还要适当选择完全不匹配的图文给机器识别,作为负样本来平衡正样本的数量。
二,给图片注入语义¶
有了训练好的CLIP模型,我们就获得了一个完美的工具,用来联系语义信息和计算机视觉信息了。那如何利用CLIP模型呢?一个很直白的思路就是,对于一段描述文字,我们先用CLIP的Text Encoder去压缩成embedding向量。在unet的去噪过程中,我们就不断地用 attention机制 给去噪的过程注入这个embedding向量,就可以不断注入语义信息了。
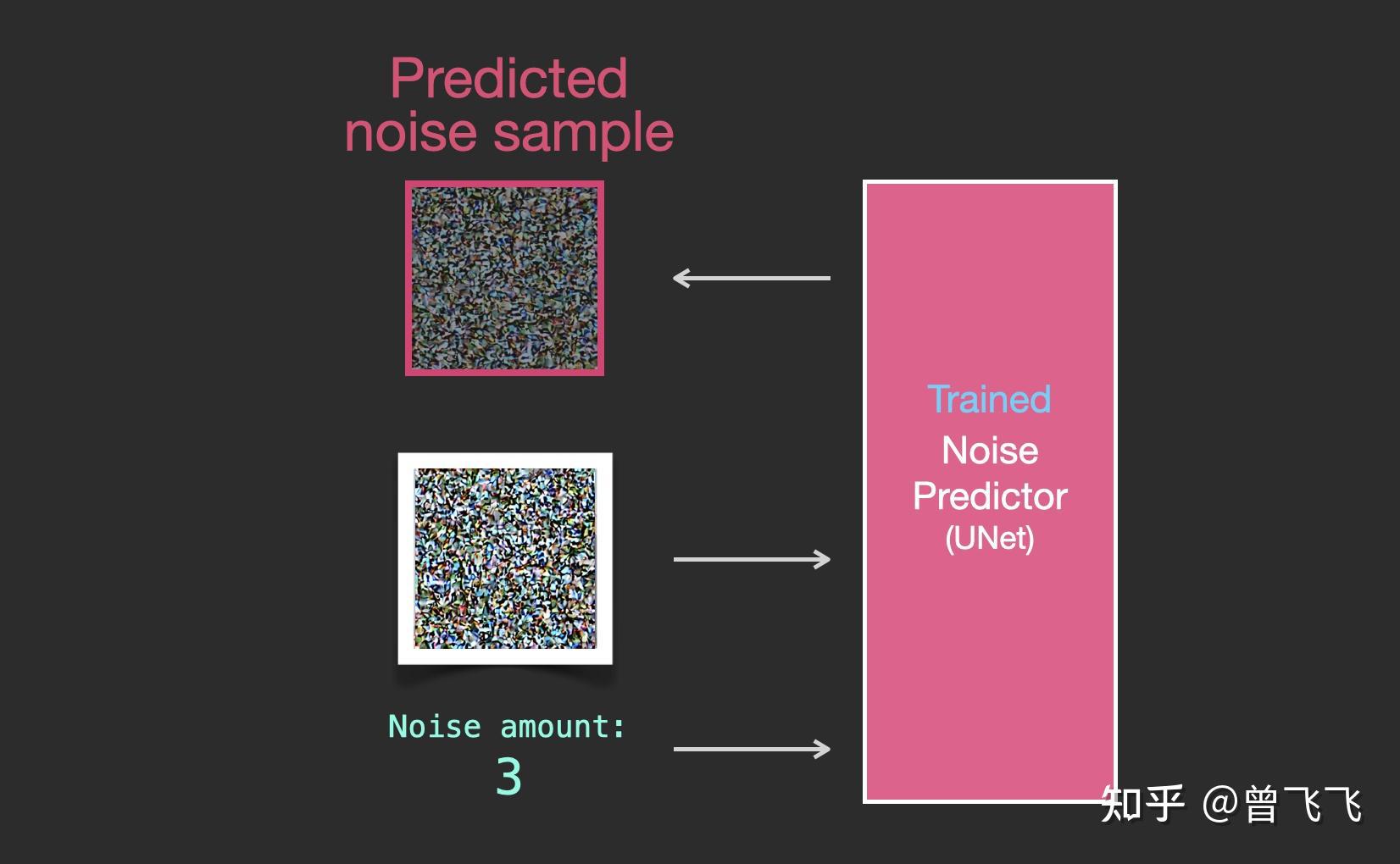
回忆一下,在上篇文章中,我们介绍了没有语义信息时unet的输入输出情况。大概就是下图这个样子,输入是噪声强度和加噪图,输出是加噪图上所加的噪声。
现在有了语义的embedding向量,稍作修改之后,我们就有了新的输入输出关系图。语义embedding向量在下图中表示为蓝色3*5的方格:

训练的数据集也添加了文字的数据对,现在输入变成了噪声强度+加噪图+文字:
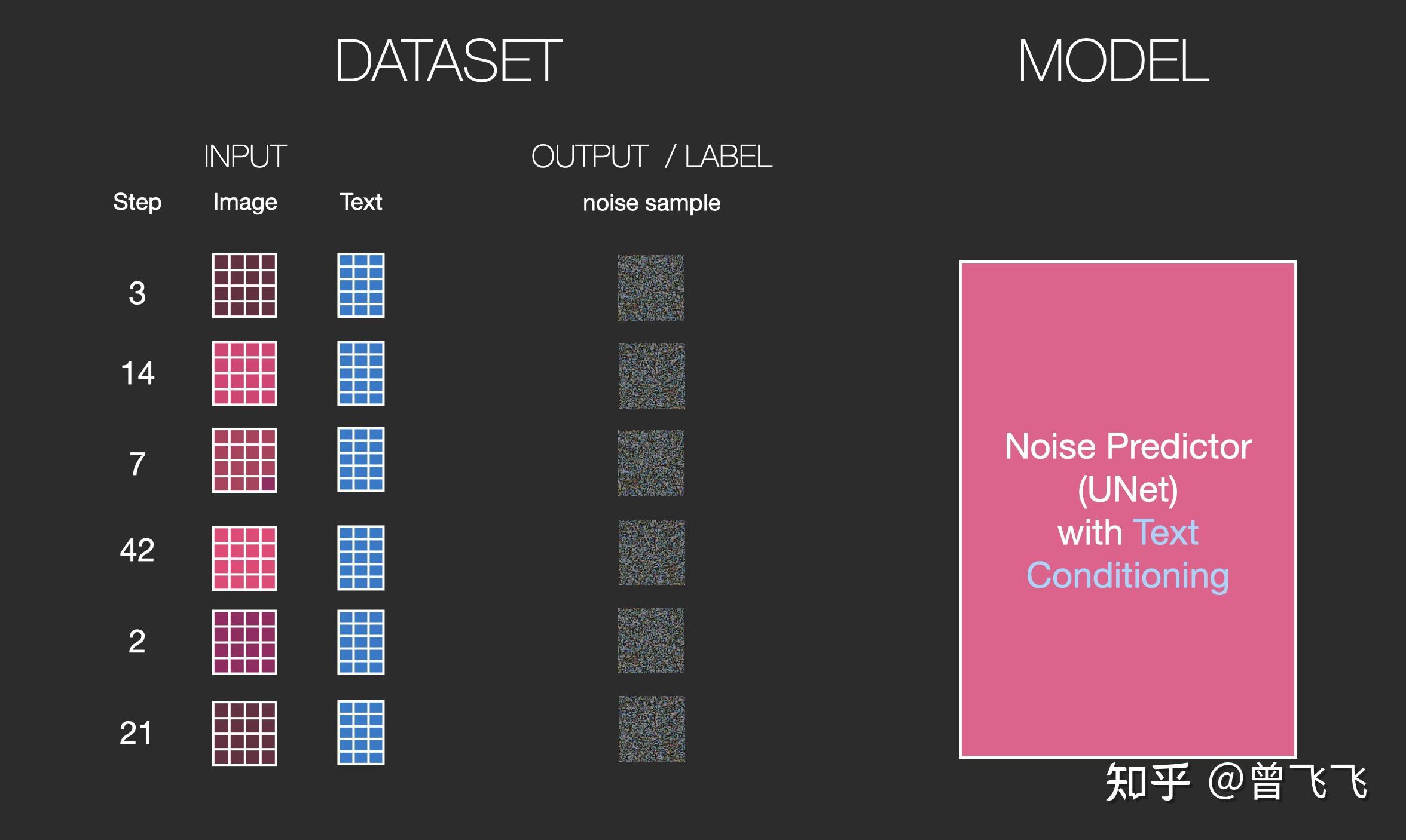
要更清楚的知道语义向量是这么作用于这个过程中的,我们必须更深入的了解一下Unet里面是怎么工作的。
1,没有文字时的Unet¶
首先,没有文字的时候,unet宏观的工作模式我们已经很清楚了。unet的输入是加噪图和噪声强度,输出是加噪图上所加的噪声:
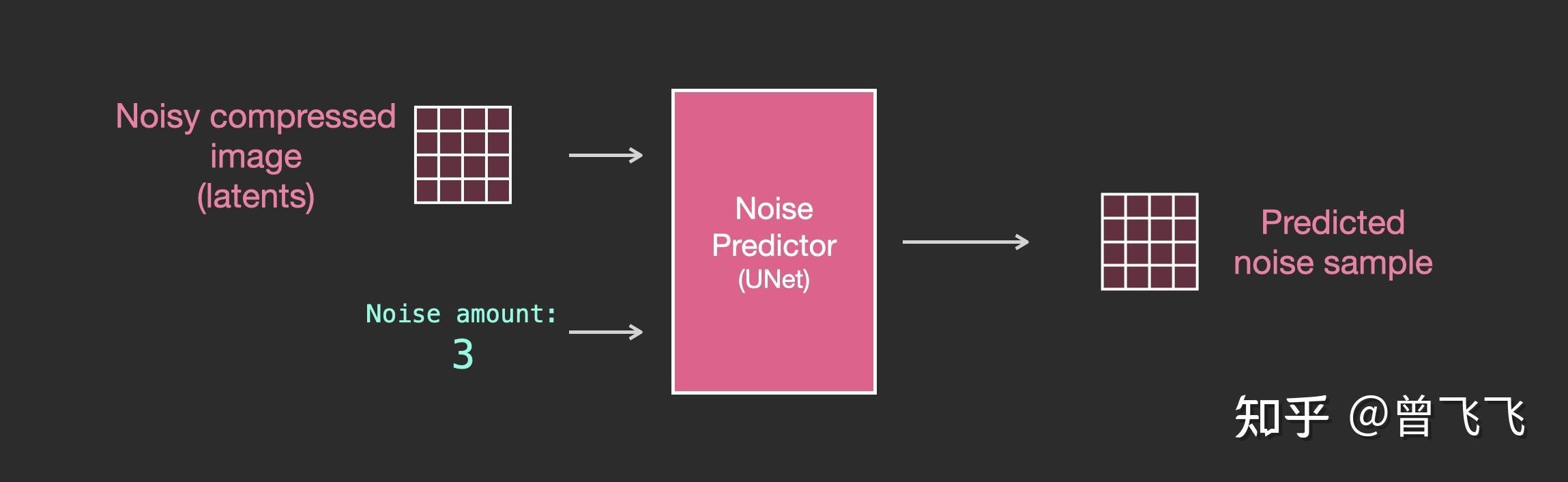
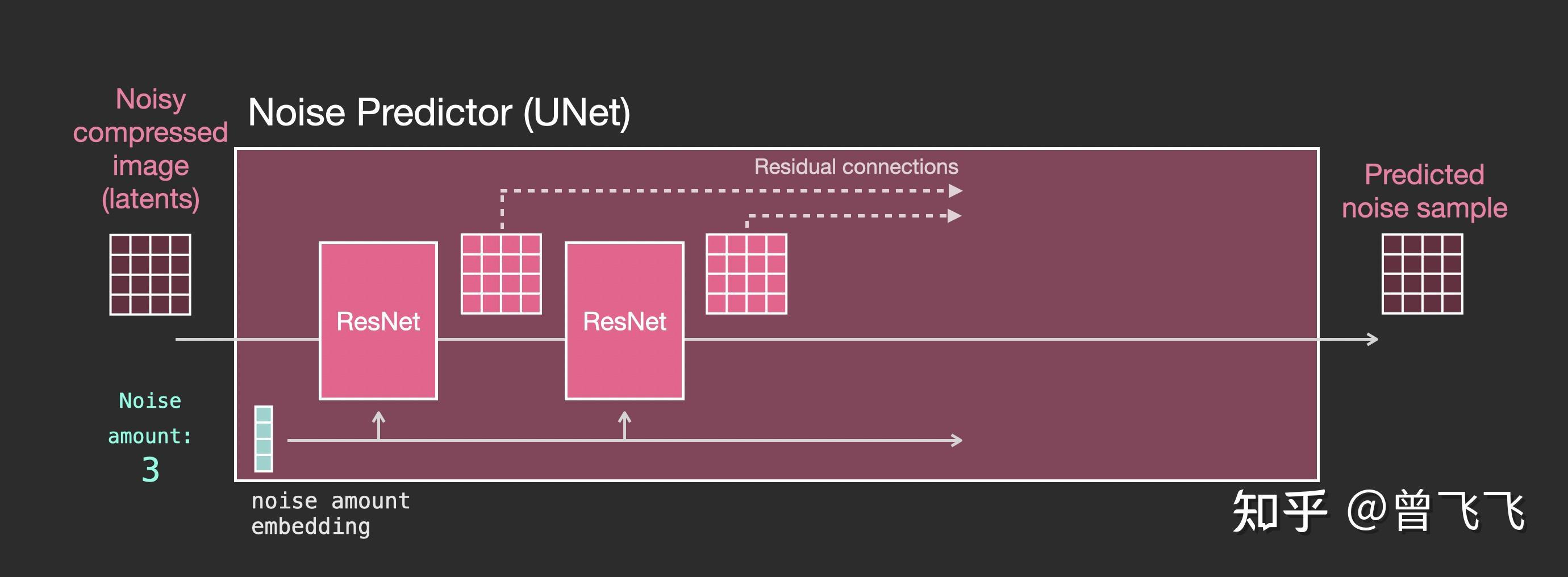
然后,当我们要更细致的了解unet里面到底是什么样的时候,就可以把上图中代表unet的小粉块放大来看。如下图所示,整个unet内部的流程特点如下
- 整个unet是由一系列 Resnet 构成的。
- 每一层的输入都是上一层的输出。
- 一些输出用residual connection直接跳跃到后面去,如下图中的虚线,这种residual+skip的操作也是很经典的unet思想。
- 噪声强度被转换成一个embedding向量 ,输入到每一个子的Resnet里面。这也是噪声强度能控制unet的底层原理所在。
2,有文字时的Unet¶
了解了没有文字时的unet是怎么工作的之后,接下来我们就要加入文字的处理了。首先,还是看宏观的输入输出,相比上面额外添加了文字embedding作为输入【下图蓝色3*5】:
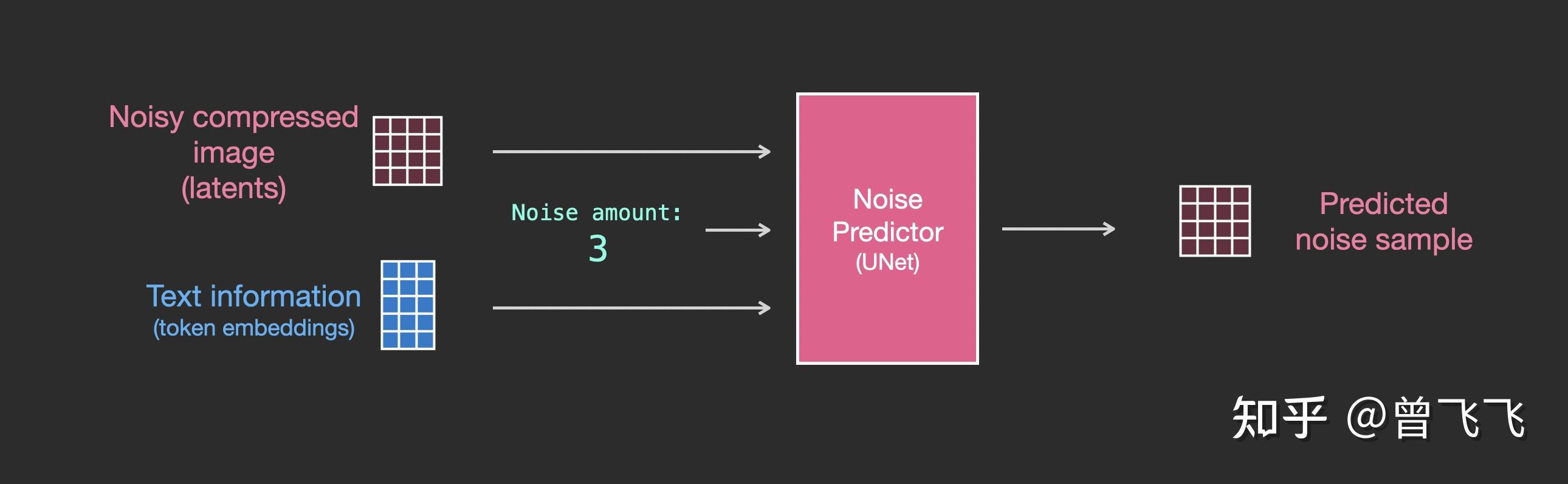
我们再细看一下粉色的unet模块里到底发生了什么。如下图所示,每个Resnet不再和相邻的Resnet直接连接,而是 在中间新增了Attention的模块 。CLIP Encoder得到的语义embedding就用这个Attention模块来处理。

注意到,Resnet模块并不直接以文字作为输入,而是使用了Attention作为后处理模块。现在Unet就可以通过这一方式成功利用CLIP的语义信息了。就此,我们也就能成功完成文生图的任务。
三,总结¶
如果你成功地看到了这里,那么首先要恭喜你看完了这三篇共计一万字的大长文。希望这三篇文章能够给你一个基本的直觉,让你明白Stable Diffusion是怎么工作的。事实上,还有很多其他的模块或者是细节,但是一旦你理解了这些基础模块的工作原理,那些附加的额外模块相信你也可以轻松理解。
最后,再简单归纳一下这篇文章的内容,给我们的Stable Diffusion的理解系列画上一个完美的句点:
- 语义信息怎么来? ——我们介绍了CLIP模型以及它的训练方式,主要运用匹配的图片对和不匹配的图片对让CLIP模型去判断,通过判断结果更新两个Encoder的参数。
- 语义信息怎么用? ——我们观察了不用语义信息的Unet,并将其推广到使用语义信息的Unet。具体来说,就是在内部的每一个小小的Resnet后面加上一个Attention模块处理语义信息。
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: 对人体及姿态问题感兴趣的大四在读生
来源: https://zhuanlan.zhihu.com/p/598070109