零基础读懂Stable Diffusion(II):怎么训练¶
由于原文篇幅较长,所以这里分为三篇文章进行讲解:
- 第一篇,主要讲“ 是什么 ”的问题,包括Stable Diffusion是什么,里面的各个模块是什么,上一篇的链接在这里。
- 第二篇,也就是本篇,主要讲“ 怎么办 ”的问题,也就是Diffusion怎么训练以及怎么使用的问题。
- 第三篇,主要讲“ 如何控制 ”的问题,具体阐述语义信息到底是怎么影响生成图片的过程的。
接下来正式进入第二篇的介绍,谈谈训练Diffusion该怎么去训练和怎么去使用的问题。
上文讲到,Stable Diffusion中有着三个主要的模块,包括一个 Text Understander 处理语义信息,一个 Image Information Creator 生成图片的隐变量,一个 Image Decoder 利用隐变量生成真正的图片。同时,对于整个图片生成的过程,我们也有了更加深入的了解。我们不仅仅知道了向量通过各个阶段时的 形状变化 ,还 可视化 了过程中噪声变为图片的全过程。因此,在大概了解Stable Diffusion的工作流程之后,我们接下来要开始学会 训练这个模型 了。
一,Diffusion怎么训练¶
Diffusion模型能够生成高质量图片,其核心原因在于我们现在有着极其强大的计算机视觉模型。只要数据集够大,我们强大的模型就能学习到任何复杂的操作。那具体diffusion里面让unet学习了怎样一个操作呢?简单来说,就是“ 去噪 ”。
那如何为去噪的任务设计数据集呢?很简单,我们只要 向普通的照片里添加噪声 ,不就有了加噪的图片了嘛。假定我们现在有一张金字塔的图片,我们用random函数生成从强到弱各个强度的噪声,比如下图中0~3共计4个强度的噪声。现在我们 选定个某个强度 的噪声,比如下图中选了噪声1,并且把这个噪声添加到图片里:
 训练集如何制作:1,选张图片 2,生成从强到弱各个强度的噪声 3,从中选个噪声(比如强度1) 4,加到图片里
训练集如何制作:1,选张图片 2,生成从强到弱各个强度的噪声 3,从中选个噪声(比如强度1) 4,加到图片里
现在,我们就制作完成了训练集里面的一张图片。按照这样的操作,选一张图片,再选一种强度的噪声混合,我们还可以制作很多训练集。比如下面就选了图书馆的一张照片,混合了强度为2的噪声,创造了一个 更模糊一点 的训练样本:

上面仅仅作为一个简单的例子,所以噪声只设置了四个档位。实际上我们可以更细腻地划分噪声的等级,将其分为几十个甚至上百个档位,这样就可以创建出成千上万个训练集。比如我们现在噪声设置成100个档位,下面就展示了利用不同的档位结合不同的图片创建6张训练集的过程:

这样的话,一组训练集包括了三样东西: 噪声强度 (上图数字), 加噪后的图片 (上图左列图片),以及 噪声图 (上图右列图片)就可以了。训练的时候我们的unet只要在已知噪声强度的条件下,学习如何从加噪后的图片中计算出 噪声图 就可以了。注意,我们并不直接输出无噪声的原图,而是让unet去 预测原图上所加过的噪声 。当需要生成图片的时候,我们用加噪图 减掉 噪声就能恢复出原图了。
具体的一个训练过程就如下图所示,一共分四步走:
- 从训练集中选取一张加噪过的图片和噪声强度,比如下面的加噪街道图和噪声强度3。
- 输入unet,让unet预测 噪声图 ,比如下图的unet prediction。
- 计算和真正的噪声图之间的误差
- 通过反向传播更新unet的参数。

那完成训练后,我们该如何生成图片呢?
二,Diffusion怎么生成图片¶
假设我们现在已经按照上面的步骤训练好了一个unet,这就意味着它就 可以成功从一个加噪的图片中推断出噪声了 。如下图中,知道噪声强度的情况下,给unet输入一张有噪图,unet就输出有噪图上面加过的噪声:
 只要知道噪声强度,训练好的unet就可以成功推断出噪声
只要知道噪声强度,训练好的unet就可以成功推断出噪声
既然现在噪声图能够被推断出来,我们只要把加噪后的图片减去这个噪声图,就可以轻松得到一张略微去噪的图片了:
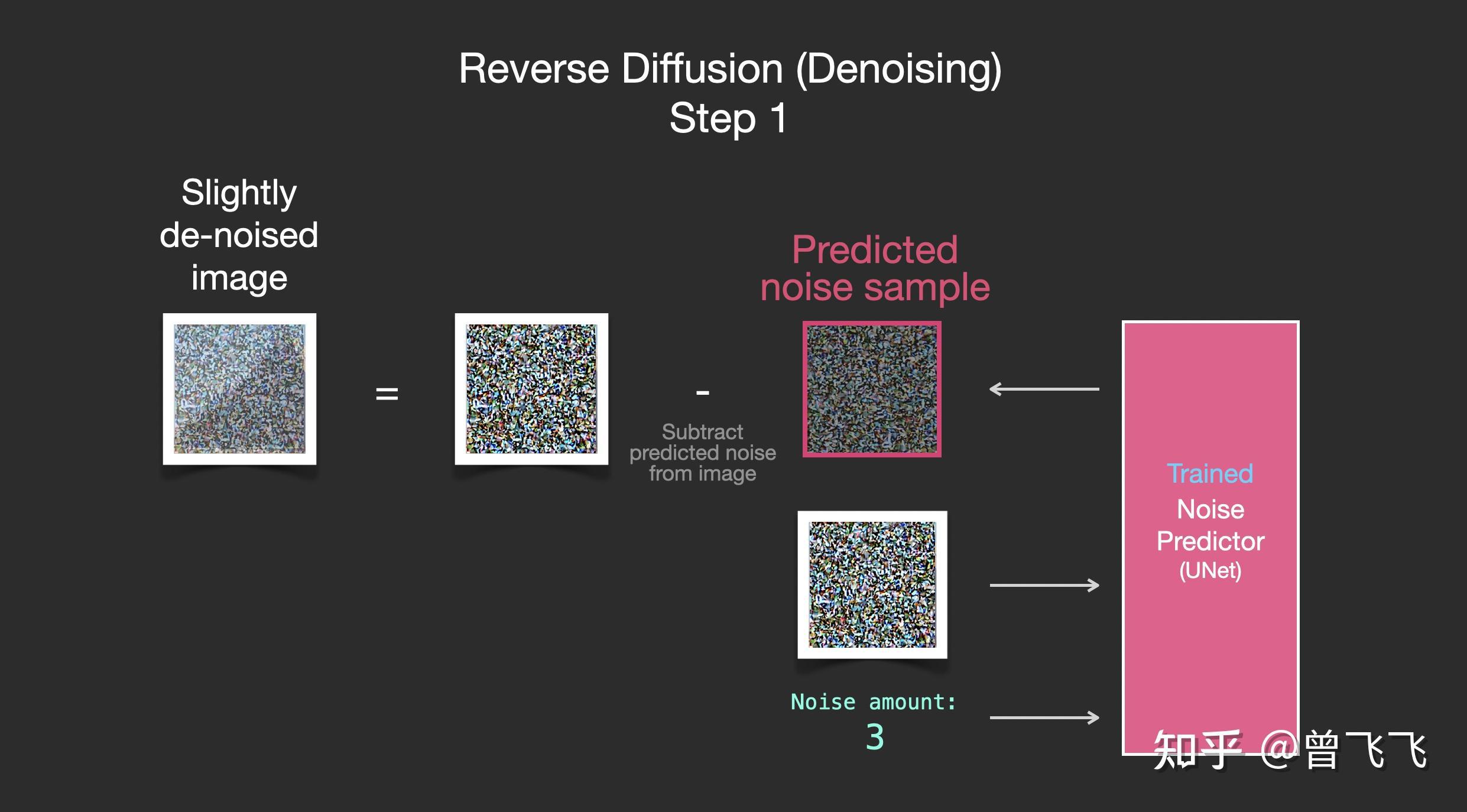
重复这个过程,预测噪声图,再减去噪声图,进行第二步去噪:

不断地重复这个过程,不断的去除一张噪声图片的噪声,最终我们就可以得到一张很棒的图片。这个图片是接近训练集分布的,它和训练集保有相同的像素规律。比如你用一个艺术家数据集去训练,它就会遵循美学的颜色分布,你用真实世界的训练集去训练,它的结果就会尽量遵循真实世界的规律。现在,你已经了解了Diffusion模型的基本规律了,这不仅仅适用于Stable Diffusion,也适用于OpenAI的Dall-E 2和Google的Imagen。
注意到上面这个过程中我们暂时还没有引入文字和语义向量的控制。也就是说,如果单纯的按照上面的流程走,我们可能能得到一些很炫酷的图片,但我们 没有办法去控制最后的结果到底是什么 。那如何引入文字控制呢?这就要使用 语言模型 和 Attention机制 来引入语义啦,这一部分内容我们放到下篇中讲解。
三、总结¶
在上一篇我们介绍完Stable Diffusion的各个模块和工作流程后,这一篇我们着重讲述了Diffusion是如何训练和推理的。文章的结尾,这里简单总结一下这篇的内容:
- Diffusion's Training: 利用 “噪声强度、噪声图、加噪后图片” 组成训练集,训练unet,使其学习如何从加噪后的图片推断出所加的噪声。
- Diffusion's Inference: 利用训练好的unet, 从纯噪声中一步一步去噪 ,得到合理正常的图片。
至于语义信息是如何控制生成图片的过程的,我们就留到下篇中再做叙述啦。下篇文章可以点击这里阅读
最后的最后,码字不易,喜欢的话可以点个赞或者收藏,作者会很开心的。后续作者也会更新更多关于深度学习领域的内容,感兴趣的话也可以关注一下哦~
凡本网注明"来源:XXX "的文/图/视频等稿件,本网转载出于传递更多信息之目的,并不意味着赞同其观点或证实其内容的真实性。如涉及作品内容、版权和其它问题,请与本网联系,我们将在第一时间删除内容!
作者: 曾飞飞 对人体及姿态问题感兴趣的大四在读生
来源: https://zhuanlan.zhihu.com/p/597732415